
Как в экселе посчитать самая частая причина увольнения
Опубликовано: 15.05.2024
Необходимость поиска наибольших и наименьших значений в любом бизнесе очевидна: самые прибыльные товары или ценные клиенты, самые крупные поставки или партии и т.д.
Но наравне с этим, иногда приходится искать в данных не топовые, а самые часто встречающиеся значения, что хоть и звучит похоже, но, по факту, совсем не то же самое. Применительно к магазину, например, это может быть поиск не самых прибыльных, а самых часто покупаемых товаров или самое часто встречающееся количество позиций в заказе, минут в разговоре и т.п.
В такой ситуации задачу придется решать немного по-разному, в зависимости от того, с чем мы имеем дело - с числами или с текстом.
Поиск самых часто встречающихся чисел
Предположим, перед нами стоит задача проанализировать имеющиеся данные по продажам в магазине, с целью определить наиболее часто встречающееся количество купленных товаров. Для определения самого часто встречающегося числа в диапазоне можно использовать функцию МОДА (MODE) :

Т.е., согласно нашей статистике, чаще всего покупатели приобретают 3 шт. товара.
Если существует не одно, а сразу несколько значений, встречающихся одинаково максимальное количество раз (несколько мод), то для их выявления можно использовать функцию МОДА.НСК (MODE.MULT) . Ее нужно вводить как формулу массива, т.е. выделить сразу несколько пустых ячеек, чтобы хватило на все моды с запасом и ввести в строку формул =МОДА.НСК(B2:B16) и нажать сочетание клавиш Ctrl+Shift+Enter.
На выходе мы получим список всех мод из наших данных:

Частотный анализ по диапазонам функцией ЧАСТОТА
Если же нужно проанализировать не целые, а дробные числа, то правильнее будет оценивать не количество одинаковых значений, а попадание их в заданные диапазоны. Например, нам необходимо понять какой вес чаще всего бывает у покупаемых товаров, чтобы правильно выбрать для магазина тележки и упаковочные пакеты подходящего размера. Другими словами, нам нужно определить сколько чисел попадает в интервал 1..5 кг, сколько в интервал 5..10 кг и т.д.
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY) . Для нее нужно заранее подготовить ячейки с интересующими нас интервалами (карманами) и затем выделить пустой диапазон ячеек (G2:G5) по размеру на одну ячейку больший, чем диапазон карманов (F2:F4) и ввести ее как формулу массива, нажав в конце сочетание Ctrl+Shift+Enter:

Частотный анализ сводной таблицей с группировкой
Альтернативный вариант решения задачи: создать сводную таблицу, где поместить вес покупок в область строк, а количество покупателей в область значений, а потом применить группировку - щелкнуть правой кнопкой мыши по значениям весов и выбрать команду Группировать (Group) . В появившемся окне можно задать пределы и шаг группировки:

. и после нажатия на кнопку ОК получить таблицу с подсчетом количества попаданий покупателей в каждый диапазон группировки:

Минусы такого способа:
- шаг группировки может быть только постоянным, в отличие от функции ЧАСТОТА, где карманы можно задать абсолютно любые
- сводную таблицу нужно обновлять при изменении исходных данных (щелчком правой кнопки мыши - Обновить), а функция пересчитывается автоматически "на лету"
Поиск самого часто встречающегося текста
Если мы имеем дело не с числами, а с текстом, то подход к решению будет принципиально другой. Предположим, что у нас есть таблица из 100 строк с данными о проданных в магазине товарах, и нам нужно определить, какие товары покупались наиболее часто?
Самым простым и очевидным решением будет добавить рядом столбец с функцией СЧЁТЕСЛИ (COUNTIF) , чтобы подсчитать количество вхождений каждого товара в столбце А:

Затем, само-собой, отсортировать получившийся столбец по убыванию и посмотреть на первые строчки.
Или же добавить к исходному списку столбец с единичками и построить по получившейся таблице сводную, подсчитав суммарное количество единичек для каждого товара:

Если исходных данных не очень много и принципиально не хочется пользоваться сводными таблицами, то можно использовать формулу массива:

Пост родился вследствие опроса в нашем телеграм канале Какие показатели текучести кадров считают в компаниях? (по ссылке результаты опроса). Я показал, что из себя представляет средний срок жизни - см. Кейс: метрики текучести персонала на примере одной компании, но самой востребованным показателем текучести персонала, который бы хотели изучить коллеги - как считать % текучести персонала в excel

* присоединяйтесь к нашему телеграм каналу @hranalitycs.
Поэтому я и решил сделал кейс по расчету текучести персонала в excel на примере данных конкретной компании.
Также рекомендую Вам этот пост Как считать текучесть персонала в R/Rstudio (кейс на примере конкретной компании)
Видео
Крайне рекомендую посмотреть видео расчета текучести в excel
Вводная
- Дата приема работника;
- Дата увольнения работника (если он работает на момент отчета, то поле остается пустым).
Формула расчета
Расчет
- Колонка D соответствует дням января - от 01 января 2018 года до 31 января.
- Напротив каждого дня нам нужно показать количество работников в статусе "работает" - этому соответствует колонка E;
- И мы также считаем количество уволенных по каждому дню - это колонка F.
Среднесписочная и количество уволенных
- =СЧЁТЕСЛИ($A$2:$A$7556,"<"&D2)-СЧЁТЕСЛИ($B$2:$B$7556,"<"&D2)
- , где
- СЧЁТЕСЛИ($A$2:$A$7556,"<"&D2) - показывает количество принятых на указанную дату
- $A$2:$A$7556 - это наша переменная "Дата поступления",
- D2 в нашем случае обозначает 01.01.2018
- формула в целом считает всех принятых в компанию ДО 01.01.2018
- СЧЁТЕСЛИ($B$2:$B$7556,"<"&D2) - показывает количество всех уволенных на указанную дату;
- $B$2:$B$7556 - переменная "дата увольнения"
- D2 - как выше уже заметили - 01.01.2018
- =СЧЁТЕСЛИ($B$2:$B$7556," дата увольнения"
- D2 - 01.01.2018
- убедиться, что ваши формулы работают корректно
- данные в системе учета вводятся корректно
Текучесть
Ну и чтобы посчитать % текучести персонала по месяцу в excel, мы
- ячейка E33 - получаем среднее значение списочного состава по месяцу
- ячейка F33 - количество уволенных за январь.
- G33 - доля уволенных
Сравнение текучести персонала по месяцам
- Январь -1, 06 % (ячейка G33);
- Февраль - 1, 04 % (K33);
- Март - 1, 45 % (O33);
- Апрель - 1, 22 % (S33).
Доверительные интервалы
- % текучести 0.010644666
- Нижняя граница ошибки 0.008232271
- Верхняя ошибка 0.013057061
- Нижняя граница ошибки 0.0116929
- % текучести 0.014500271
- Верхняя ошибка 0.017307642
Хи квадрат
Еще один способ сравнения текучести по месяцам. Изучить Хи квадрат можно:
- Самостоятельно по книге Е. Сидоренко Математические методы в психологии - в интернете ее легко можно скачать.
- В моих постах Как считать Хи квадрат в excel и Как в excel быстро считать ожидаемые частоты для вычисления Хи квадрат, но в этом случае уже надо понимать логику применения критерия - зачем и куда его тыкать.
- Мой семинар Аналитика для HR - ближайший будет 18-19 октября в Москве.
Другие способы
-
- инструмент карты Шухарта, чтобы понимать отклонение; - более глубокий метод на основе временных рядов - в нашем случае мы должны март сравнивать не с январем, а с мартом прошлого года - выявлять сезонные тенденции.
12 комментариев:
А запланированные увольнения учли? Если в марте у части сотрудников закончился срочный ТД? Их увольнение не должно влиять на показатель текучести.
Спасибо за формулу расчёта Особенно как самостоятельно посчитать среднесписочную. Но обращайте внимание на правила учёта В текучесть не входят запланированные увольнения (к примеру срочные ТД) смерть сотрудников и т.п.
Никита.
конечно, я об этом думал, но эта проблема решается легко: мы добавляем третью колонку с причинами увольнений.
И у нас формула меняется в СЧЕТЕСЛИ на СЧЕТЕСЛИМН - мы добавляем еще одно условие - причина увольнения.
таким же образом, мы, кстати, считаем добровольную / не добровольную текучесть - это тоже важно.
И (!) если у нас возникнет потребность посчитать текучесть по разным филиалам / позициям персонала, то мы добавляем соответствующие колонки / переменные, задаем новые условия и считаем по ним
Всё верно. Я предлагаю добавить эти уточнения в статью, чтобы у менее искушенных коллег сразу складывалось правильное понимание термина и они делали поправки на эти данные.
я думаю, что коллегам достаточно прочитать комменты)
ну либо пришлите данные с новыми вводными
Если копать глубже в ньюансы расчета то появляется еще больше ангументов к "счетеслимн"
1. Декретницы - по-хорошему не должны попадать в среднесписочную, хотя от компании к компании варьируется взгляд на это
2. "Потеряшки" - распространенная ситуация на производстве когда сотрудник просто не приходит на работу. Таких тоже не совсем корректно считать в среднюю численность в мае, если в январе они перестали ходить на работу.
3. Перевод через увольнение - сотрудник переходит со внешнего совместительства на внутреннюю полную ставку и приходится его увольнять, хотя по факту человек работает и не уволился. Либо человек уволился в одной стране присутствия и принялся в другой в эту же компанию, т.н. техническое увольнение.
И получается что простых дат увольнения и приема не хватает и если использовать только их то результаты могут сильно исказиться :)
Рамис, добавьте третью колонку
по факту могу сказать, что в компании чаще просто вообще нет правил подсчета среднесписочной и по конкретному человеку принимают конкретное решение, и тогда отсев происходит по полю ФИО - распространенная практика?
а по пункту 3. Перевод через увольнение
в чем проблема? Он уволен, но тут же принят и снова попадает в среднеспиосочную
мы же не модель оттока строим, где надо его стаж учитывать
Проблема не в среднесписочной, а в том что такой сотрудник попадет в список уволенных, хотя по-хорошему не должен.
Про правила подсчета среднесписочной да, скорее соглашусь, иногда практикуется пофамильное исключение из списка уволенных.
Ну и правила подсчета все равно вырабатываются из специфики бизнеса. Если в компании нет проблем с потеряшками, то нет и необходимости учитывать дату с которой сотрудник перестал ходить на работу.
В целом у меня еще комментарий - на мой взгляд намного удобнее считать среднесписочную по каждому сотруднику в формате от 0 до 1 для каждого конкретного месяца. Т.е. был активен весь месяц - 1, принялся или уволился в середине месяца - 0.5, если был в декрете/потерялся/еще не принялся/ГПХ - 0. Так расчет получается структурированее и легче для обработки и можно учесть больше вышеописанных ньюансов.
Рамис, вот это я вообще не понял
"Проблема не в среднесписочной, а в том что такой сотрудник попадет в список уволенных, хотя по-хорошему не должен."
а в чем здесь проблема? ну попал он в список уволенных и что? С т.з. построения среднесписочной и текучести персонала нас все равно. Если у вас другая задача встает, то ее можно решать другими способами, у меня такой задачи не встает.
Вот этот комментарий я вообще не понял
"В целом у меня еще комментарий - на мой взгляд намного удобнее считать среднесписочную по каждому сотруднику в формате от 0 до 1 для каждого конкретного месяца. Т.е. был активен весь месяц - 1, принялся или уволился в середине месяца - 0.5, если был в декрете/потерялся/еще не принялся/ГПХ - 0. Так расчет получается структурированее и легче для обработки и можно учесть больше вышеописанных ньюансов."
мы считаем среднесписочную (должны считать как указано в Консультант Плюс) как среднее всех дней по месяцу, как вы будете здесь учитывать 1, 05, 0 - я не понимаю.
После написания поста (спустя время сам с трудом понял о чем написано) с призывом помочь решить проблему, после чего через некоторое время было найдено решение, но публикация ответа затянулась на пол года)).
Суть задачи: Нужно чтобы из поступающих данных от сайта в таблицу (к примеру по типу: "ключ, дата, название . значение") можно было на отдельном листе отфильтровать "ключи" в фиксированном порядке в выбранном диапазоне дат (от и до) и сравнить с предыдущим периодом.
Решение: нужно добавить к таблице получаемых данных столбцы отвечающие за поиск "Вспомогательный столбец и функция ИНДЕКС для извлечения записей с И критерием", но с некоторыми модификациями для отбора определённых ключей "ЕСЛИОШИБКА + ПОИСКОПЗ".
Более подробно на скрине:
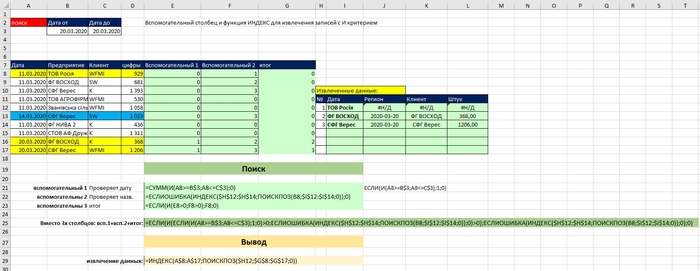
Как вы могли заметить, на скриншоте изображена таблица в более простом исполнение, где все видео более наглядно, тут без сравнения результатов (это просто), она будет чуть ниже уже готовая + черновик. На черновом варианте уже видно что "ключ" не подходящим критерием остался пустой, а в случае повторяющегося ключа был выбран более свежий по дате.
Пример готовой таблицы и черновик можно глянуть по ссылке.
Дубликаты не найдены
Таблица нужна была людям плохо понимающие Эксель, а нужно было только менять даты и все готово. Вся проблема в том что таблица должна была считать/сравнивать с выбранными диапазонами дат + не малый
камень в огород фильтра это масштаб таблицы: более 90 столбцов и пару тысяч строк и из них нужно было оставить 50

Визуализация гистограммы фигурами и рисунками в Excel
Мы попытаемся несколько освежить их внешний вид и сделать его более приятным для восприятия и чтения информации. Мы уже разбирали как можно построить прогресс-бары (линейный и круговой), такие графики тоже могут отлично подойти для создания дашборда и отображения KPI.
Различные фигуры (прямоугольники с закругленными краями, полукруги, стрелки) и рисунки отлично помогут нам в создании и визуализации таких графиков, и в целом немного коснемся темы инфографики.
00:00 - О вариантах добавления фигур и рисунков на графики
01:06 - Построение диаграммы с добавлением фигур на график
06:40 - Построение диаграммы с добавлением рисунков на график
Как перевести данные в тысячи/миллионы/… в Excel?
Сегодня обсудим способы перевода числовых данных в тысячи, миллионы, миллиарды и другие порядки в Excel для сокращения записей (например, как число вида 123 456 перевести в 123,4 тыс. или 987 654 321 в 988 млн.).
Мы можем изменить вид числа как с помощью применения формул (делением содержимого ячейки на требуемый делитель), так и сделать перевод числа с помощью настройки формата отображения ячейки.
Также научимся добавлять различные подписи к записи, к примеру, "тыс. руб." для перевода сумм в тысячи рублей и другие подобные подписи.
Построение радиальной гистограммы в Excel | Радиальная диаграмма
Чем же особенна радиальная гистограмма?
В общем и целом это гистограмма построенная в радиальной системе координат (всем нам привычная классическая линейная гистограмма использует евклидову геометрию). Грубо говоря мы берем обычную гистограмму и сворачиваем ее в круг, и сегодня мы как раз будем учиться как можно построить радиальную диаграмму.
00:00 - Начало
00:28 - Особенности радиальной гистограммы (отличие от линейной)
00:44 - Недостатки графика
01:12 - Построение радиальной диаграммы
01:50 - Меняем строки и столбцы местами для корректного отображения рядов
02:16 - Формируем дополнительный ряд для диаграммы
03:31 - Особенности настройки параметров (процент заполнения кольца)
03:47 - Убираем заливку на ненужных столбцах
04:12 - Расширяем столбцы на графике (оптимизируем полезное пространство)
04:43 - Добавляем подписи данных на ряды
06:21 - Меняем заливку столбцов на подходящие цвета
06:51 - Настраиваем угол поворота диаграммы
07:36 - Примеры радиальных гистограмм
Умная таблица в Excel | Как сделать умную таблицу?
Разберем как сделать умную таблицу в Excel (т.е. преобразовать обычную таблицу в умную), как сделать обратное действие (т.е. уже снаоборот, убрать умную таблицу и преобразовать ее в обычную), в принципе поймем какие свойства появляются при работе с умными таблицами и прочие полезные приемы.
00:00 - Начало
00:39 - Создание умной таблицы в Excel
01:45 - Преимущества при работе с умными таблицами
02:22 - Автоматическое добавление фильтра
02:43 - Имя умной таблицы
03:28 - Автоматическое изменение размера
03:50 - Копирование формулы на весь столбец
04:17 - Копирование формулы для новых строк
04:57 - Закрепление заголовков при прокрутке
05:56 - Имена для отдельных элементов таблицы и работа с ними
06:33 - Дополнительные настройки (вкладка Конструктор)
06:59 - Как убрать умную таблицу и сделать из нее обычную
08:00 - Недостатки умной таблицы
Количество и сумма ячеек по цвету в Excel
Сегодня поговорим про простой способ как посчитать количество, и как суммировать ячейки по цвету в Excel.
С помощью пользовательских функций реализуем суммирование по цвету заливки ячейки (или по цвету текста), а также разберем аналогичный пример и для подсчета количества ячеек одинакового цвета.
Тайм-коды для удобства навигации
00:44 - Суммирование ячеек по цвету
02:48 - Подсчет количества ячеек по цвету
03:34 - Изменение функций для расчетов по цвету текста
03:55 - Особенности применения функций
Лайфхаки с Excel
Как же часто случается, что по забывчивости на вопрос: "Сохранить изменения?" - нажимаешь "Нет"! И вот вы уже думаете, что последняя пара часов ушла вникуда. Однако есть отличный шанс восстановить утраченное. В Excel 2010 нажмите на Файл, выберите Последние. В правом нижнем углу экрана появится опция Восстановить несохраненные книги. В версии 2013 года путь такой: Файл — Сведения — Управление версиями.

Чтобы выделить все ячейки, не нужно долго прокручивать мышкой. Достаточно будет нажать Ctrl + A или специальную кнопку в углу листа.

Бывает, что в самом начале работы с таблицей вы еще не можете представить, как лучше подать информацию - в ячейках или в столбцах. Функция транспонирования облегчит эту задачу. Выделите нужное количество ячеек и скопируйте их, зажав Ctrl + C. Теперь нужно выбрать нужный столбец и вставить данные с опцией Транспонировать.

Фишки Excel
Нажмите на ячейку, в которой вы хотите увидеть результат, и вбейте туда знак " story-block story-block_type_image">

Вы легко можете поменять регистр всей текстовой информации, выбрав необходимую функцию. ПРОПИСН - сделать все буквы прописными, ПРОПНАЧ - сделать прописной первую букву в каждом слове. Функция СТРОЧН, соответственно, делает все буквы строчными.
Как перейти к нужному листу

Все, кто работает с Excel ежедневно, знают, как трудно бывает найти нужный лист, особенно если их количество перевалило за 10. Для быстрого перемещения кликните правой кнопкой по кнопке прокрутки (она находится в нижней левой части экрана). Теперь вы можете перейти на любой нужный лист мгновенно.
В Excel есть прикольная функция, которая позволяет вывести в столбце маленькую диаграмму, отображающую положение дел в других ячейках. Благодаря этой штуке вы наглядно можете показать клиенту или руководителю, что все ваши труды не напрасны и за этот год видны улучшения. Нажмите Вставка, перейдите в группу Спарклайны и выберите опцию График или Гистограмма (что больше нравится).

Диаграмма в Эксель
Пять первых шагов к освоению программы Excel.
Базовый видеокурс по работе в программе Эксель.
- как на основе таблицы создать диаграмму
- как вывести книгу Эксель на печать
5 простых приемов для эффективной работы в Excel
Отличная функция, благодаря которой можно избавить себя от долгого заполнения одинаковых по своей сути форм. Например, у нас есть список из десятка фамилий и имен, который мы хотим сократить. И вот, чтобы не заполнять все поля заново, Excel (начиная с версии 2013) предлагает заполнить их сам.

Очень часто при работе с программой приходится открывать огромное количество самых разных файлов. Чтобы быстро перемещаться между ними, достаточно нажать одновременно клавиши Ctrl + Tab. Это, ко всему прочему, работает и в браузерах.
Если вам нужно быстро перенести ячейку или столбец, выделите их и наведите мышку на границу. Ждите, пока указатель сменится на другой. После этого можно смело перетаскивать их куда угодно. Для копирования ячейки или столбца нужно проделать то же самое, только с зажатой кнопкой Ctrl.

Сделать это довольно просто: выделите нужный столбец, нажмите на вкладку Данные и воспользуйтесь функцией Фильтр. Теперь вы можете выбрать любой столбец и избавиться от пустых полей.

Эта функция будет полезна всем, кто хочет временно спрятать нужную информацию. С помощью этой опции можно также оставлять какие-то комментарии и заметки, которые не будут перемешиваться с основным текстом. Выделите интересующую вас ячейку, перейдите в меню Формат и нажмите Скрыть и отобразить. Так вам откроются доступные функции.

Формулы Гугл Таблиц, которых нет в Excel
Формулы Google таблиц унаследованы от Excel, но есть и более продвинутые функции: формулы массива, ArrayFormula, текстовые функции и формулы импорта данных из других таблиц (IMPORTRANGE) и сайтов (IMPORTHTML, IMPORTXML). Эти возможности позволяют как работать в гугл таблицах быстрей, так и избежать возможных ошибок (из-за большого количества формул).
0:00 - Приветствие Гугл драйв в деле!
0:16 - Плюсы гугл таблиц
0:35 - Формулы массива UNIQUE FILTER SORT
2:00 - ARRAYFORMULA
3:20 - Текстовые функции JOIN и SPLIT
4:04 - Интеграции и импорт GOOGLETRANSLATE IMAGE GOOGLEFINANCE
4:30 - IMPORTHTML IMPORTXML IMPORTRANGE

Даркнет и Служба внешней разведки

На сайте Службы Внешней Разведки (СВР) пользователями была обнаружена единственная кнопка на английском языке "Report Information"

По ссылке инструкция как из-за пределов России передать ценные разведданные по сети TOR
Сразу вспомнился шедевр братьев Коэнов "После прочтения сжечь". Сцена когда американская труженица фитнес центра пытается заработать на искусственные сиськи, путем продажи компакт диска с шпиОнской информацией в русское посольство
В фильме показано как непросто приходится бессознательным американским гражданам в их попытках достучаться до российской разведки с целью обмена родины на пышный силикон
Но цифровая трансформация российской государственной машины пошла навстречу и таким алчным иностранным гражданам. Теперь каждый может почувствовать себя шпионом не выходя из дома
Успешный опыт внедрения цифровых ГосУслуг для населения переносится на внешний контур
Оплата скорее всего будет в биткоинах по курсу ЦБ на дату слива информации.
Также утверждается, что это первая приемная в даркнете среди всех европейских разведывательных ведомств
Базы данных - почему бизнес их боится / избегает

Раньше странно было наблюдать, почему при автоматизации бизнес процессов заказчики боятся баз данных
Цепляние за эксель у многих происходит до последнего
Вроде бы уже все, можно отпустить и двигаться дальше. Но нет. Давайте лучше эксель
Переход к базе данных это следующий уровень сложности, знаний для контроля над которым просто нет
Тут они уже нутром понимают, что обратной дороги не будет. Придётся зависеть от этих мутных ИТ-шников, с их sql запросами и прочей магией
В экселе - все понятно, вот файл, в нем закладки с табличками
А база данных это где?
Еще хорошо если на локальном сервере. По крайне мере может покажут стационарный комп с мигающими лампочками. В мозгах может появится успокаивающая ассоциация, что этот ящик и есть база данных. Тогда его можно в охраняемую комнату запереть и спать спокойно.
А если база данных в "облаке"?
В газетах вон постоянно пишут про хакеров и как из облаков данные утекают
Тут все надежно, проверено мудростью предков, и есть панацея от всех проблем: ctrl+alt+delete
В Екатеринбурге сотрудник сотовой компании продавал данные абонентов
В Екатеринбурге попал под следствие 25-ти летний продавец-консультант офиса продаж одного из крупных операторов сотовой связи.
Пост родился вследствие опроса в нашем телеграм канале Какие показатели текучести кадров считают в компаниях? (по ссылке результаты опроса). Я показал, что из себя представляет средний срок жизни - см. Кейс: метрики текучести персонала на примере одной компании, но самой востребованным показателем текучести персонала, который бы хотели изучить коллеги - как считать % текучести персонала в excel
* присоединяйтесь к нашему телеграм каналу @hranalitycs.
Поэтому я и решил сделал кейс по расчету текучести персонала в excel на примере данных конкретной компании.
Также рекомендую Вам этот пост Как считать текучесть персонала в R/Rstudio (кейс на примере конкретной компании)
Видео
Крайне рекомендую посмотреть видео расчета текучести в excel
Вводная
- Дата приема работника;
- Дата увольнения работника (если он работает на момент отчета, то поле остается пустым).
Формула расчета
Расчет
- Колонка D соответствует дням января - от 01 января 2018 года до 31 января.
- Напротив каждого дня нам нужно показать количество работников в статусе "работает" - этому соответствует колонка E;
- И мы также считаем количество уволенных по каждому дню - это колонка F.
Среднесписочная и количество уволенных
- =СЧЁТЕСЛИ($A$2:$A$7556,"<"&D2)-СЧЁТЕСЛИ($B$2:$B$7556,"<"&D2)
- , где
- СЧЁТЕСЛИ($A$2:$A$7556,"<"&D2) - показывает количество принятых на указанную дату
- $A$2:$A$7556 - это наша переменная "Дата поступления",
- D2 в нашем случае обозначает 01.01.2018
- формула в целом считает всех принятых в компанию ДО 01.01.2018
- СЧЁТЕСЛИ($B$2:$B$7556,"<"&D2) - показывает количество всех уволенных на указанную дату;
- $B$2:$B$7556 - переменная "дата увольнения"
- D2 - как выше уже заметили - 01.01.2018
- =СЧЁТЕСЛИ($B$2:$B$7556," дата увольнения"
- D2 - 01.01.2018
- убедиться, что ваши формулы работают корректно
- данные в системе учета вводятся корректно
Текучесть
Ну и чтобы посчитать % текучести персонала по месяцу в excel, мы
- ячейка E33 - получаем среднее значение списочного состава по месяцу
- ячейка F33 - количество уволенных за январь.
- G33 - доля уволенных
Сравнение текучести персонала по месяцам
- Январь -1, 06 % (ячейка G33);
- Февраль - 1, 04 % (K33);
- Март - 1, 45 % (O33);
- Апрель - 1, 22 % (S33).
Доверительные интервалы
- % текучести 0.010644666
- Нижняя граница ошибки 0.008232271
- Верхняя ошибка 0.013057061
- Нижняя граница ошибки 0.0116929
- % текучести 0.014500271
- Верхняя ошибка 0.017307642
Хи квадрат
Еще один способ сравнения текучести по месяцам. Изучить Хи квадрат можно:
- Самостоятельно по книге Е. Сидоренко Математические методы в психологии - в интернете ее легко можно скачать.
- В моих постах Как считать Хи квадрат в excel и Как в excel быстро считать ожидаемые частоты для вычисления Хи квадрат, но в этом случае уже надо понимать логику применения критерия - зачем и куда его тыкать.
- Мой семинар Аналитика для HR - ближайший будет 18-19 октября в Москве.
Другие способы
-
- инструмент карты Шухарта, чтобы понимать отклонение; - более глубокий метод на основе временных рядов - в нашем случае мы должны март сравнивать не с январем, а с мартом прошлого года - выявлять сезонные тенденции.
12 комментариев:
А запланированные увольнения учли? Если в марте у части сотрудников закончился срочный ТД? Их увольнение не должно влиять на показатель текучести.
Спасибо за формулу расчёта Особенно как самостоятельно посчитать среднесписочную. Но обращайте внимание на правила учёта В текучесть не входят запланированные увольнения (к примеру срочные ТД) смерть сотрудников и т.п.
Никита.
конечно, я об этом думал, но эта проблема решается легко: мы добавляем третью колонку с причинами увольнений.
И у нас формула меняется в СЧЕТЕСЛИ на СЧЕТЕСЛИМН - мы добавляем еще одно условие - причина увольнения.
таким же образом, мы, кстати, считаем добровольную / не добровольную текучесть - это тоже важно.
И (!) если у нас возникнет потребность посчитать текучесть по разным филиалам / позициям персонала, то мы добавляем соответствующие колонки / переменные, задаем новые условия и считаем по ним
Всё верно. Я предлагаю добавить эти уточнения в статью, чтобы у менее искушенных коллег сразу складывалось правильное понимание термина и они делали поправки на эти данные.
я думаю, что коллегам достаточно прочитать комменты)
ну либо пришлите данные с новыми вводными
Если копать глубже в ньюансы расчета то появляется еще больше ангументов к "счетеслимн"
1. Декретницы - по-хорошему не должны попадать в среднесписочную, хотя от компании к компании варьируется взгляд на это
2. "Потеряшки" - распространенная ситуация на производстве когда сотрудник просто не приходит на работу. Таких тоже не совсем корректно считать в среднюю численность в мае, если в январе они перестали ходить на работу.
3. Перевод через увольнение - сотрудник переходит со внешнего совместительства на внутреннюю полную ставку и приходится его увольнять, хотя по факту человек работает и не уволился. Либо человек уволился в одной стране присутствия и принялся в другой в эту же компанию, т.н. техническое увольнение.
И получается что простых дат увольнения и приема не хватает и если использовать только их то результаты могут сильно исказиться :)
Рамис, добавьте третью колонку
по факту могу сказать, что в компании чаще просто вообще нет правил подсчета среднесписочной и по конкретному человеку принимают конкретное решение, и тогда отсев происходит по полю ФИО - распространенная практика?
а по пункту 3. Перевод через увольнение
в чем проблема? Он уволен, но тут же принят и снова попадает в среднеспиосочную
мы же не модель оттока строим, где надо его стаж учитывать
Проблема не в среднесписочной, а в том что такой сотрудник попадет в список уволенных, хотя по-хорошему не должен.
Про правила подсчета среднесписочной да, скорее соглашусь, иногда практикуется пофамильное исключение из списка уволенных.
Ну и правила подсчета все равно вырабатываются из специфики бизнеса. Если в компании нет проблем с потеряшками, то нет и необходимости учитывать дату с которой сотрудник перестал ходить на работу.
В целом у меня еще комментарий - на мой взгляд намного удобнее считать среднесписочную по каждому сотруднику в формате от 0 до 1 для каждого конкретного месяца. Т.е. был активен весь месяц - 1, принялся или уволился в середине месяца - 0.5, если был в декрете/потерялся/еще не принялся/ГПХ - 0. Так расчет получается структурированее и легче для обработки и можно учесть больше вышеописанных ньюансов.
Рамис, вот это я вообще не понял
"Проблема не в среднесписочной, а в том что такой сотрудник попадет в список уволенных, хотя по-хорошему не должен."
а в чем здесь проблема? ну попал он в список уволенных и что? С т.з. построения среднесписочной и текучести персонала нас все равно. Если у вас другая задача встает, то ее можно решать другими способами, у меня такой задачи не встает.
Вот этот комментарий я вообще не понял
"В целом у меня еще комментарий - на мой взгляд намного удобнее считать среднесписочную по каждому сотруднику в формате от 0 до 1 для каждого конкретного месяца. Т.е. был активен весь месяц - 1, принялся или уволился в середине месяца - 0.5, если был в декрете/потерялся/еще не принялся/ГПХ - 0. Так расчет получается структурированее и легче для обработки и можно учесть больше вышеописанных ньюансов."
мы считаем среднесписочную (должны считать как указано в Консультант Плюс) как среднее всех дней по месяцу, как вы будете здесь учитывать 1, 05, 0 - я не понимаю.
Одним из самых распространенных методов, применяемых в статистике для изучения данных, является корреляционный анализ, с помощью которого можно определить влияние одной величины на другую. Давайте разберемся, каким образом данный анализ можно выполнить в Экселе.
- Назначение корреляционного анализа
- Выполняем корреляционный анализ
- Метод 1: применяем функцию КОРРЕЛ
- Метод 2: используем “Пакет анализа”
Назначение корреляционного анализа
Корреляционный анализ позволяет найти зависимость одного показателя от другого, и в случае ее обнаружения – вычислить коэффициент корреляции (степень взаимосвязи), который может принимать значения от -1 до +1:
-
если коэффициент отрицательный – зависимость обратная, т.е. увеличение одной величины приводит к уменьшению второй и наоборот.
Сила зависимости определяется по модулю коэффициента корреляции. Чем больше значение, тем сильнее изменение одной величины влияет на другую. Исходя из этого, при нулевом коэффициенте можно утверждать, что взаимосвязь отсутствует.
Выполняем корреляционный анализ
Для изучения и лучшего понимания корреляционного анализа, давайте попробуем его выполнить для таблицы ниже.
![Таблица в Excel для выполнения корреляционного анализа]()
Здесь указаны данные по среднесуточной температуре и средней влажности по месяцам года. Наша задача – выяснить, существует ли связь между этими параметрами и, если да, то насколько сильная.
Метод 1: применяем функцию КОРРЕЛ
В Excel предусмотрена специальная функция, позволяющая сделать корреляционный анализ – КОРРЕЛ. Ее синтаксис выглядит следующим образом:
Порядок действий при работе с данным инструментом следующий:
- Встаем в свободную ячейку таблицы, в которой планируем рассчитать коэффициент корреляции. Затем щелкаем по значку “fx (Вставить функцию)” слева от строки формул.
![Вставка функции в ячейку таблицы Эксель]()
- В открывшемся окне вставки функции выбираем категорию “Статистические” (или “Полный алфавитный перечень”), среди предложенных вариантов отмечаем “КОРРЕЛ” и щелкаем OK.
![Выбор оператора КОРРЕЛ для вставки в ячейку таблицы Excel]()
Метод 2: используем “Пакет анализа”
Альтернативным способом выполнения корреляционного анализа является использование “Пакета анализа”, который предварительно нужно включить. Для этого:
- Заходим в меню “Файл”.
![Переход в меню Файл в Экселе]()
- В перечне слева выбираем пункт “Параметры”.
![Переход к параметрам Excel]()
- В появившемся окне кликаем по подразделу “Надстройки”. Затем в правой части окна в самом низу для параметра “Управление” выбираем “Надстройки Excel” и щелкаем “Перейти”.
![Переход к управлению надстройками в параметрах Excel]()
- В открывшемся окошке отмечаем “Пакет анализа” и подтверждаем действие нажатием кнопки OK.
![Включение надстройки Пакет анализа в Эксель]()
Все готово, “Пакет анализа” активирован. Теперь можно перейти к выполнению нашей основной задачи:
Заключение
Таким образом, выполнение корреляционного анализа в Excel – достаточно автоматизированная и простая в освоении процедура. Все что нужно знать – где найти и как настроить необходимый инструмент, а в случае с “Пакетом решения”, как его активировать, если до этого он уже не был включен в параметрах программы.
Читайте также:
- Нужно ли в сзв тд при увольнении указывать предыдущую запись если сведения уже подавались
- Внешний совместитель уволился с основного места работы что делать
- Как уволить главного бухгалтера при реорганизации
- Увольнение по соглашению сторон плюсы и минусы для работника
- Могут ли уволить вич инфицированного с работы






