
Как хранить график работы в базе данных
Опубликовано: 17.09.2024
Есть самописная система учета заявок по ремонту оборудования, в качестве бд используется Microsoft Sql Server редакция Express.

Возникла необходимость учитывать простой оборудования в рабочее время.
Помогите модифицировать ( читать как какие таблицы необходимо добавить) приведенную схему так, что бы можно было получать время простоя оборудования в рабочее время. График работы может меняться (для каждой единицы оборудования). Историю изменения режимов работы необходимо сохранить, что бы при изменении режима бы возможность получить корректные данные. Заранее спасибо
Под простоем оборудования в рабочее время подразумевается следующее:
Предположим у нас есть закрытая заявка зарегистрированная в 10:00 закрытая в 23:15 этого же дня, режим работы данной единицы оборудования предположим с 07:00 до 17:00 тогда простой будет равен 7 часам, другой пример: тот же режим работы, заявка зарегистрирована в 16:00 закрыта в 10:15 следующего дня простой в этом случае будет 4 часа 15 минут (1 час предыдущего дня и 3:15 текущего)

В таблицу RequestHistories или Requests , добавляете дату_время начала(Created) и окончания (Closed) ремонта в виде колонок типа datetime. Далее в тексте называю это таблицу просто Requests . И создаем следующие таблицы:
Основная таблица расписания работы оборудования:
В этой таблице для каждой единицы оборудования должна быть как минимум одна запись с расписанием. Рекомендую добавлять ее автоматически, в триггере при создании оборудования. Для упрощения запросов к этой таблице период действия записи делаем двумя полями - датой начала и окончания действия. Для активной в данный момент записи датой окончания ставим 1 янв 3000 года. (Можно null, но с ним потом работать менее удобно). Записи в таблице для конкретной единицы оборудования должны идти без разрывов в днях и без пересечений. Желательно делать контроль триггерами. Например, если есть запись для оборудования ID 1 заканчивающаяся 10 февраля 2016, после нее должна быть запись с 11 февраля 2016 по 3000 год.
Поле weekday число с установленными битами соответствующими рабочим дням недели оборудования. При Российских настройках MSSQL дни (номера бит) начинаются с понедельника. 0й бит не используется. Рабочая неделя Пон-Пят - установлены биты с 1 по 5 итого значение 62. Без выходных - 254. При Американских настройках MSSQL неделя будет начинаться в воскресенья, поэтому убедитесь, какой именно день недели первый на вашем сервере.
Исключения из стандартного расписания для праздников и других особых случаев:
В эту таблицу заранее на каждый год надо положить записи с праздничными днями. Для таких, общих, записей EquipmentId=NULL . Если согласно производственного календаря на данный год какой либо выходной объявляется перенесенным рабочим (суббота 20 февраля 2016, например) - то для него кладется запись с isWork=1 - таким образом он становится исключением из стандартной проверки дней недели.
Если для какой то конкретной единицы оборудования существует нестандартное расписание праздников или конкретные выходные дни, в которое оно должно работать - в эту таблицу кладем запись с заполненным EquipmentId и isWork рабочий(1)/нерабочий(0).
Возможно имеет смысл заводить промежуточную таблицу с группами оборудования, для удобства задачи расписания сразу группе. Так же, возможно, стоит сделать в EquipmentMode записи с общим расписанием (eqId=NULL), что бы не создавать для каждой единицы отдельно. Решайте сами, как удобнее на вашем предприятии будет.
И еще нам понадобится служебная таблица с порядковыми номерами, для размножения записей в запросе. Количество записей в ней должно превышать максимально возможную продолжительность ремонта в днях:
Предполагаемая логика работы расписания: Если для данной единицы оборудования есть собственная запись в таблице holidays - то брать или не брать данный день в расчет берется только из нее. Иначе если в holidays есть общая запись на данный день - берем ее. Иначе сверяем день недели с битовой маской в EquipmentMode .
Запрос выбирающий простой по каждому дню по каждой единице оборудования выглядит примерно так:
Выборку этого запроса группируете как вам необходимо и суммируете. Лишние поля из основной части запроса лучше убрать, я их ставил для удобства отладки и просмотра результата по дням. SQLFIDDLE

Отличительной чертой нашего времени является постоянный рост объема деловой информации. Дизайнеры, маркетологи, копирайтеры, представители IT-профессий, а также компании, работающие с огромными массивами данных, постоянно нуждаются в надежном месте, в котором можно было бы хранить ценные файлы. Если раньше их держали на дискетах, флешках и компакт-дисках, то сейчас лучше всего отправлять их в облачные хранилища.
Облачное хранилище: что это такое?
В общем и целом, это специально выделенное место на серверах, куда любой пользователь может закачать различные документы: текстовые файлы, любимые аудиозаписи и видеоролики, картинки, гифки, переписку из мессенджеров и многое другое. При этом серверы могут находиться где угодно: в Европе, Азии или Северной Америке.
Механизм облачного хранилища очень прост: нужно установить клиентское приложение и зарегистрироваться в нем. После чего можете спокойно сбрасывать в «облако » любую информацию, обмениваться ей с коллегами, обновлять ее, просматривать и так далее. Доступ к нему можно получить с любого устройства и из любого места, в котором есть Интернет.
Поскольку данные бывают разные, то и хранить их лучше в подходящих для этого местах. По типу организации облачные хранилища делятся на:
- файловые,
- блочные,
- объектные,
- базы данных.
Поговорим о каждом типе подробнее.
Файловое хранилище
В основе файловой системы лежит иерархическая структура: корневая запись, от которой отходят данные о файлах и их атрибутах. Все они, в свою очередь, организованы в удобную структуру каталогов – з ная имя того или иного документа, доступ к нему можно получить, щелкнув мышью по его имени. С ними можно осуществлять любые операции – открывать, изменять, переименовывать, удалять, копировать, перемещать в другую папку.
Файловое хранилище может быть двух видов: физическим и виртуальным. В первом случае данные сохраняются на жестком диске, во втором – на виртуальном. Последний имеет намного больший объем чем жесткий, а еще туда можно настроить удаленный доступ. В качестве примера можно привести Dropbox , « Облако Mail.Ru», «Google Диск», «Яндекс. Диск» и другие аналогичные им сервисы.
Преимущества:
- Простая и понятная структура.
- В таком хранилище легко ориентироваться, искать нужные документы.
Недостатки:
- Ограниченность в объеме, по мере заполнения которого падает скорость доступа, а вместе с ней и производительность.
Для чего подходит: для работы с небольшими объемами разны данных.

Блочное хранилище
В блочном хранилище структура размещения та же, но все попадающие туда файлы делятся системой на блоки, каждому из которых присваивается свой идентификатор. С его помощью система собирает файлы в случае надобности.
Преимущества:
- Каждая пользовательская среда находится отдельно, за счет чего можно рассортировывать данные и обеспечить отдельный доступ к ним.
- БХ обеспечивает повышенную производительность: благодаря хост-адаптеру шины, который разгружает процессор и освобождает его ресурсы для выполнения других задач.
Недостатки:
- Оно дороже, и им трудно управлять, поскольку работа с блоками создает дополнительную нагрузку на базу данных.
- Оно, как и файловое, ограничено в объеме.
Для чего подходит: для работы с корпоративными базами данных
Объектное хранилище
Это самый популярный тип хранилища. Вместо файловой системы в нем есть плоское пространство, состоящее из множества объектов, каждый из которых состоит из идентификатора и метаданных. Идентификатор – это присвоенный адрес, в роли которого выступает 128-битное число. Зная его можно без труда найти нужный файл. Метаданные (информация о файле) – его имя, размер, координаты и другая информация.
Объектные хранилища бывают частными или публичными. В первом случае оно создается в частном облаке, во втором – облако берут в аренду у провайдера публичных облаков.
Достоинства:
- Возможность работы с колоссальным объемом информации. Общий объем данных, хранящихся в Haystack Facebook, оценивается в 357 петабайт.
- Возможность хранения резервных копий данных, особенно тех, от которых зависит жизнедеятельность системы (например, файлы для аварийного восстановления).
- Возможность проверки корректности файлов и обеспечения быстрого доступа к ним.
Недостатки:
- Сложно называть объекты.
- Во многих объектных хранилищах отсутствует интерфейс для загрузки и управления файлами.
Для чего подходит: для хранения больших данных, текстовых документов, изображений, медиафайлов, переписок и многого другого.
База данных
База данных – это совокупность определенной информации, хранящаяся в строго установленном порядке на физических или виртуальных носителях. Она управляется специальной программой под названием СУБД (Система Управления Базами Данных). СУБД позволяет обрабатывать любые тексты, графику, медиа; с ними можно делать все что угодно: хранить, анализировать, тестировать продукты и обновления, запускать новые проекты.
Она очень хорошо подходят для постоянных типовых операций. Например, туда записывается информация о заказах, поступающих в интернет-магазин, на основе которой приложение автоматически выписывает счет на оплату. Примером такой базы может стать нереляционная высокопроизводительная СУБД Redis, она хранит данные в оперативной памяти.
Базы данных могут находиться либо на сервере, либо в облаке. Облачные СУБД сегодня являются самыми популярными в своей области. Согласно исследованиям Market Realist, их используют 35% респондентов, экспериментируют с ними 14%, планируют внедрение – 12%.
Преимущества:
- Облачные базы данных имеют практически неограниченный объем хранения.
- Есть функция резервного копирования.
- Они обладают высоким внешним и внутренним уровнем безопасности, который обеспечивается техническими средствами и экспертами.
- Поддержка многозадачного и многопользовательского режимов.
Недостатки:
- Сложность управления, что требует затрат на соответствующий персонал и ПО.
- В случае нахождения их на физическом носителе имеют ограниченный объем, так что может потребоваться увеличение дискового пространства.
- Высокая стоимость разработки и эксплуатации.
Для чего подходят: для управления однородными массивами данных.
Чего ждать в будущем
В перспективе нас ждет появление еще одного типа хранилищ – вычислительного, вся работа которого основана на обработке данных в процессе перемещения в слой хранения, что позволяет не отвлекать на выполнение операций ресурсы центрального процессора. По своей доступности, экономичности и надежности облачное хранилище пока остается основным местом для безопасного хранения данных.
В первую очередь сделаю акцент именно на том, где хранить данные компании в рабочем пространстве. Если у вас такого до сих пор нет, вам нужно срочно его заиметь. Почему это важно именно сейчас, я уже говорил, когда объяснял как организовать работу на удаленке . Это история про CRM и про то, что данный инструмент призван не только лишь вести учет продаж, как все привыкли думать. Тем не менее потребность в CRM кратно увеличивается из-за перевода на удаленку именно продавцов.
Объясняю важность хранения персональных данных компании.
Практически любой бизнес завязан на продажах. Поэтому давайте представим, что вам приходится (срочно или планово) упомянутый отдел продаж перевести на удаленную работу. Как правило, сотрудники этого отдела остаются работать в офисе даже тогда, когда бухгалтерия и отдел кадров там давно перестали появляться. Почему? Существует ряд вопросов, которые руководителю сложно решить таким образом, чтобы сохранить качественную коммуникацию с клиентами, безопасность информации и эффективность работы команды.
Сразу скажу, что если вы ваша база данных – это таблица Excel, то безопасность под вопросом даже если отдел продаж работает из офиса.
Я хочу сейчас подробнее остановиться на каждом проблемном сценарии, который может возникнуть в случае удаленной работы отдела продаж и рассказать как CRM (оно же единое рабочее пространство) поможет в хранении данных клиентов компании.
- Сложности с доступом к контактам. Это означает, что база не изменяется в режиме реального времени так, чтобы обновления были доступны всем и сразу.
CRM обеспечивает единый доступ к базе контактов, которая хранится внутри системы. А также делает возможным быстрый поиск по ней, что существенно экономит время.
- Нет понимания, все ли входящие запросы обработаны. Даже не так. Внесены ли все в базу? Как проверить, не был ли кто-то из клиентов, которые обращались к вам, потерян или забыт? Человеческий фактор никто не отменял – ошибиться, отвлечься, забыть может кто угодно.
Когда вы используете CRM, каждый новый звонок, сообщение в чате, письмо на электронной почте, обращение из соцсетей автоматически становится новым клиентом, внесенным в вашу базу. Таким образом, никто не забыт, все заявки обработаны и репутация сохранена (сарафанное радио может ведь как приводить новых клиентов, так и не давать им прийти).
Кроме этого, клиент может обратиться к вам из любого удобного ему канала связи (viber, whatsapp, telegram), а вы при этом будете видеть все обращения и сможете отвечать на них в одном месте – в CRM – и для этого вам не нужно иметь дополнительные аккаунты во всех мессенджерах.
- Путь клиента – непонимание на какой стадии клиент и кто из менеджеров им занимается. Во-первых, при наличии CRM такой проблемы просто нет – вы видите всю информацию как по клиенту, так и по нагрузке на каждого менеджера (поэтому можете ее контролировать). Но это еще не все. Есть возможность прямо в CRM создавать быстрые чаты для обсуждения сделок, лидов, компаний и контактов.
- При увольнении сотрудник может унести вашу базу контактов с собой. Хотя не только при увольнении. Вдруг кому-то вздумается делиться вашими наработками с конкурентами? Когда вы для ведения бизнеса и хранения информации используете CRM – вы обеспечиваете себе информационную безопасность, так как любое действие можно ограничить правами доступа. Это позволяет открывать доступ только к выделенной части базы данных или вовсе запретить ее экспорт.
Сообразительный менеджер, конечно, все равно может делать скриншоты или фотографии, но таким образом он унесет только малую часть данных и ему придется проделать еще огромную дополнительную работу по ее структурированию. Таких людей подобный труд обычно настолько утомляет, что они даже не берутся за него.
Ну как, убедил, что для хранения данных компании лучше использовать CRM?
Я раскрыл самые очевидные проблемы отдела продаж на удаленке и далеко не все преимущества CRM. Ясно, что хранить в ней можно не только контакты клиентов, но и создавать внутри целые базы знаний, инструкции и корпоративные документы. И все это с гарантией безопасности и быстрой доступности.
Среди самых важных характеристик любой базы данных следует назвать производительность, надежность и простоту администрирования. Знание того, как большинство СУБД физически хранят данные во внешней памяти, представление о параметрах этого хранения и соответствующих методах доступа может очень помочь при проектировании баз данных, обладающих заданной производительностью.
Хранение данных во внешней памяти в известных СУБД (Oracle, IBM DB2, Microsoft SQL Server, CA-OpenIngres, решения от Sybase и Informix и др.) организовано очень похожим образом.
Организация хранения
Основными единицами физического хранения являются блок данных, экстент, файл (либо раздел жесткого диска). Логический уровень представления информации включает пространства (либо табличные пространства). Блок данных (block) или страница (page) является единицей обмена с внешней памятью. Размер страницы фиксирован для базы данных (Oracle) или для ее различных структур (DB2, Informix, Sybase) и устанавливается при создании. Очень важно сразу правильно выбрать размер блока: в работающей базе изменить его практически невозможно (для этого часто проводят ряд испытаний базы данных-прототипа).
Размер блока оказывает большое влияние на производительность базы данных — при больших размерах скорость операций чтения/записи растет (особенно это характерно для полных просмотров таблиц и операций интенсивной загрузки данных), однако возрастают накладные расходы на хранение (база увеличивается) и снижается эффективность индексных просмотров. Меньший размер блока позволяет более экономно расходовать память, но вместе с тем относительно дорог. Длинные блоки (16, 32 или 64 Кбайт) лучше использовать для больших объектов данных: полнотекстовые фрагменты, мультимедиа-объекты, длинные строки и т.п. Короткие блоки (2 или 4 Кбайт) лучше подходят для значений числовых типов, недлинных строк, значений даты и времени. Следует также учитывать размер блока ОС, он должен быть кратен размеру блока базы данных. Малый размер блока лучше подходит для систем оперативной обработки транзакций, потому что, если сервер блокирует данные на уровне блоков, то это позволяет большему числу пользователей работать, не мешая друг другу (рис. 1). В системах поддержки принятия решений, для которых более критичным является не общая пропускная способность (количество транзакций в единицу времени), а среднее время отклика (response time), больший блок предпочтительнее.
Администратор отводит пространство для базы данных на внешних устройствах большими фрагментами: файлами и разделами диска. В первом случае доступ к диску осуществляется операционной системой, что дает определенные преимущества, например, работа с файлами средствами ОС. Во втором случае с внешним устройством работает сам сервер. При этом достигается более высокая производительность; кроме того, использование дисков необходимо в случае, если кэш ОС не может работать в режиме сквозной (write-through) записи. Диски особенно эффективны для ускорения операций записи данных (подобный механизм поддерживается Oracle, DB2 и Informix; например, в DB2 данная единица размещения называется контейнером).
Пространством внешней памяти, отведенным ему администратором, сервер управляет с помощью экстентов (extent), т.е. непрерывных последовательностей блоков. Информация о наличии экстентов для объекта схемы данных находится в специальных управляющих структурах, реализация которых зависит от СУБД. На управление экстентами (выделение пространства, освобождение, слияние) тратятся определенные ресурсы, поэтому для достижения эффективности нужно правильно определять их параметры. СУБД от Oracle, IBM, Informix позволяют определять параметры этих структур, а в Sybase экстенты имеет постоянный размер, равный 8 страницам. Уменьшение размера экстента будет способствовать более эффективному использованию памяти, однако при этом возрастают накладные расходы на управление большим количеством экстентов, что может замедлить операции вставки большого количества строк в таблицу. Кроме того, сервер может иметь ограничение на максимальное количество экстентов для таблицы. При слишком большом размере экстентов могут возникнуть проблемы с выделением для них необходимого количества памяти. Обычно определяется размер начального экстента, размер второго и правило определения размеров следующих экстентов. На рис. 2 иллюстрируется взаимосвязь блоков, экстентов и файлов баз данных.
В Informix существует еще одна единица физического хранения, промежуточная между файлом (или разделом диска) и экстентом, — это «чанк» (от английского chunk, что дословно переводится как «емкость»). Чанк позволяет более гибко управлять очень большими массивами внешней памяти. В одном разделе диска или файле администратор может создать несколько чанков. Чанк также служит единицей зеркалирования.
Общим для СУБД Oracle, DB2 и Informix является понятие пространства (для Oracle и DB2 это табличное пространство). Различные логические структуры данных, такие как таблицы и индексы, временные таблицы и словарь данных размещены в табличных пространствах. В DB2 и Informix дополнительно можно устанавливать размер страницы отдельно для каждой из этих структур. Группировка хранимых данных по пространствам производится по ряду признаков: частота изменения данных, характер работы с данными (преимущественно чтение или запись и т.п.), скорость роста объема данных, важность и т.п. Таким образом, например, только читаемые таблицы помещаются в одно пространство, для которого установлены одни параметры хранения, таблицы транзакций размещаются в пространстве с другими параметрами и т.д. (рис. 3).
Одна логическая единица данных (таблица или индекс) размещается точно в одном пространстве, которое может быть отображено на несколько физических устройств или файлов. При этом физически разнесены (располагаться на разных дисках) могут не только логические единицы данных (таблицы отдельно от индексов), но и данные одной логической структуры (таблица на нескольких дисках). Такой способ хранения называется горизонтальной фрагментацией: таблица делится на фрагменты по строкам. В Oracle вместо термина «фрагментация» используется «секционирование» (partitioning). Фрагментация — один из способов повышения производительности.
Могут применяться различные схемы записи данных во фрагментированные таблицы. Одна из них — круговая (round-robin), когда некоторая часть вставляемых в таблицу строк записывается в первый фрагмент, другая часть — в следующий и так далее по кругу. В данном случае за счет распараллеливания может быть увеличена производительность операций модификации данных и запросов. Существует и другая схема, включающая логическое разделение строк таблицы по ключу («кластеризация»). Данная схема позволяет избежать перерасхода процессорного времени и уменьшить общий объем операций ввода/вывода. Ее суть в том, что при создании таблицы все пространство значений ключа таблицы разбивается на несколько интервалов, а строкам с ключами, принадлежащими разным интервалам, назначаются различные месторасположения. Впоследствии, при обработке запроса, данная информация учитывается оптимизатором. Если производится поиск по ключу, то оптимизатор может удалять из рассмотрения фрагменты таблицы, не удовлетворяющие условию выборки. Например, создание кластеризованной таблицы будет выглядеть следующим образом (этот и все остальные SQL-скрипты приведены для Oracle):
Здесь создаются два раздела part1 и part2, каждый из которых размещен в своем табличном пространстве (tblspace1 и tblspace2). Записи со значением поля num от 1 до 499 будут располагаться в первом разделе, а записи с номерами от 500 до 1000 — во втором (рис. 4).
Тогда при запросе:
оптимизатор будет производить поиск только в разделе part1, что может дать ощутимый выигрыш в производительности в таблице с десятками тысяч строк.
Подобные механизмы фрагментации данных поддерживают практически все современные СУБД, что часто используется при создании систем высокой производительности.
Методы доступа
Современные СУБД предоставляют достаточно широкий набор различных методов доступа, которые чаще всего являются теми или иными видами индексирования — способа отображения ключа индексирования в адрес хранимой записи. Используются следующие типы индексных структур: на основе B-дерева (B-tree); на основе хэш-функции или хеширование (hashing); на базе битовых шкал или индексов (bitmap). Индекс может служить различным целям: для ускорения доступа к записям одной таблицы и для ускорения операций соединения, тогда он называется индексом соединения. Если в качестве ключа индексирования используется некоторая функция атрибутов таблицы, такой индекс называют «основанным на функции» (function-based). Скажем, можно создать такой индекс для ускорения поиска с учетом регистра символов для таблицы Famous (таблица 1):
Отличают также «кластеризованный» (clustered) индекс. При его использовании все записи таблицы упорядочиваются по его ключу; поэтому кластеризованный индекс более экономно расходует память и обычно быстрее опрашивается. Для таблицы, таким образом, можно создать лишь один такой индекс.
B-деревья универсальны и обеспечивают хорошую скорость доступа как при просмотрах по диапазонам, так и при выборке единичной записи по значению ключа, однако характеризуются относительно большим объемом памяти для хранения и затратами на поддержание в актуальном состоянии, включающими обычно балансировку дерева. Такой индекс имеет один существенный недостаток — он может быть использован только в запросах по ведущим столбцам. Например, если в таблице Famous создан составной индекс по столбцам fullname, birth и sex:
смогут использовать этот индекс, а в следующих запросах:
оптимизатор не сможет им воспользоваться, что связано с архитектурными особенностями данного типа индексирования. В данном примере индекс может быть использован при запросах по fullname, birth, sex либо fullname, birth либо только fullname. Несмотря на этот недостаток, индексы B-деревьев наиболее распространены и используются во всех рассматриваемых СУБД. Для B-дерева можно задать «степень использования страницы индекса» (fillfactor); так, в Oracle используются параметры PCTUSED и PCTFREE для блоков базы данных в том числе и индексных. При создании индекса его страницы заполняются только на указанный процент (рис. 5). При увеличении процента использования страницы увеличится скорость операций изменения индекса, однако возрастут также расходы на хранение и может увеличиться время выполнения запросов.
Каждая СУБД может иметь ряд дополнительных параметров, предоставляющих разработчику расширенные возможности конфигурирования В-деревьев.
Хэш-индекс имеет небольшие накладные расходы на хранение, однако требует, чтобы распределение значений ключа индексирования было относительно постоянно, в противном случае потребуется частая переделка индекса на основе новой хэш-функции. Индексы на основе хэш-функций хорошо подходят для различного рода справочных таблиц. При этом не требуется, чтобы индексируемый столбец имел много повторяющихся значений, как того требуют битовые индексы.
Битовые индексы также очень компактны и полезны для столбцов с большим процентом повторения значений ключа. Обычно используют следующее правило: если количество повторяющихся значений столбца более 99% от общего количества строк таблицы, тогда целесообразно рассмотреть использование битового индекса. Так, таблица Famous могла бы выиграть от использования двух битовых индексов — по столбцам SEX и MARRIED.
Битовые индексы обладают очень важным свойством: если производится запрос, включающий сложное условие выборки, которое составлено из предикатов OR, AND, NOT и «=», то оптимизатор может использовать имеющиеся по конкретным столбцам битовые индексы, объединяя их. B-деревья этого делать не позволяют (для этого потребовалось бы построить составной индекс по этим столбцам, специально для ускорения данного запроса). В рассматриваемом примере запрос вида:
может использовать оба битовых индекса emp_ind_02 и emp_ind_03. Однако тот же запрос не сможет использовать два отдельных индекса по этим же столбцам. Битовые карты полезны в хранилищах, где преобладают длинные транзакции и данные читаются чаще чем записываются, однако они неэффективны в приложениях с короткими транзакциями, характерными для OLTP-систем.
В DB2 используется оптимизированный вариант B-дерева с двунаправленными указателями и «упреждающей регистрацией обновлений» (write-ahead logging), что позволяет ускорить вставку данных. При создании индекса можно также использовать некоторые опции, например, указать серверу о необходимости хранить в структуре индекса дополнительные часто запрашиваемые значения атрибутов.
В СУБД Oracle помимо многочисленных индексов используются «индексно-упорядоченные» (index-organized) таблицы и кластеры. В первом случае вся таблица индексирована по первичному ключу и организована в виде B-дерева.
Подобный метод организации хранения хорошо подходит для часто опрашиваемых больших (более 5 тыс. строк) и очень больших таблиц с небольшим объемом операций, для которых критично время выполнения запроса на точное совпадение по первичному ключу, например:
Экономия времени при выполнении таких запросов может составлять от 15 до 400% в зависимости от длины строки [1].
Кластер Oracle — это структура для хранения одной или нескольких таблиц, главным образом служащая для ускорения операций их соединения, в которой строки таблиц, удовлетворяющие условию соединения, хранятся вместе. Столбцы, используемые для соединения, называются кластерным ключом. Значения кластерного ключа сохраняются один раз (дубликаты исключаются). Для доступа по кластерному ключу могут использоваться как B-деревья, так и хэш-структуры, в этом случае кластер является хэш-кластером. Стоит также упомянуть битовый индекс соединения (bitmap join), ускоряющий операции объединения таблиц. В Sybase используются B-деревья, а индекс может быть как кластеризованным так и обычным. В Informix можно применять кластеризованные, битовые и индексы, основанные на функции.
Проблемы управления внешней памятью
Распространенной проблемой для администраторов при управлении физическим хранением является фрагментация различных структур внешней памяти, которая чаще обусловлена операциями удаления. В отличие от преднамеренной фрагментации, такая «фрагментация» обычно ухудшает производительность. Встречается фрагментация на уровне блоков, когда в блоке остается свободное пространство после удаления строк из таблицы, на уровне экстентов, когда заполненные экстенты чередуются с незаполненными, появившимися после операций удаления таблиц, и т.п. Укажем лишь часть из проблем, которые могут быть обусловлены фрагментацией.
- Выделение свободного пространства. При вставке строк в таблицу СУБД выдает сообщение о нехватке свободного пространства, хотя на первый взгляд пространства достаточно. Пространство выделяется экстентами и, если в базе данных нет непрерывного свободного блока нужного размера, то выдается это сообщение.
- Замедление операций вставки в таблицу. В [2] приводится пример с таблицей базы данных, в которую в ходе выполнения ночного пакетного задания происходит вставка большого количества строк. Для того чтобы уменьшить время его выполнения был в несколько раз увеличен размер вновь выделяемых экстентов, благодаря чему снизились накладные расходы на выделение экстентов, а скорость выполнения пакетного задания возросла на 30%.
- Расход свободного пространства и общее увеличение времени обработки данных. В случае сильной фрагментации обе величины могут вырасти вдвое.
Фрагментация неизбежна и поэтому является нормальным явлением, и не всегда ухудшает характеристики базы данных. Индексы также подвержены проблемам фрагментации пространства, и могут стать несбалансированными, поэтому SQL-оператор ALTER INDEX обычно имеет опцию REBUILD, позволяющую перестроить индекс. Индекс также можно удалить и создать заново даже в работающей базе данных.
Заключение
Эффективность использования любых методов доступа зависит от распределения данных в запрашиваемых таблицах, от стратегии работы оптимизатора СУБД и от возможностей диалекта SQL. Поэтому приведенные рекомендации носят достаточно общий характер — все определяется конкретной ситуацией. Решения, принимаемые на этапах физического проектирования и настройки, чаще всего представляют собой компромисс между достижением требуемых характеристик, которые часто противоречат друг другу. За выигрыш в скорости обработки запросов, которую дает индекс, приходится платить дополнительными ресурсами памяти на его размещение и процессорным временем для его поддержки в актуальном состоянии. К сожалению, трудно привести конкретные оценки: многое зависит от конфигурации сервера, настройки ОС и СУБД и т.п.
Рассмотренный перечень методов доступа не является полным. Описаны лишь распространенные технологии, которые можно назвать традиционными. Например, за кадром остались возможности современных СУБД, связанные с реализацией расширяемой системы типов данных. Сюда относят технологии расширителей (Extender) IBM, DataBlade (Informix) и картриджей (Oracle). Тем не менее, перечисленный арсенал средств достаточно богат сам по себе. Адекватное представление об этих средствах позволяет сделать проектируемые базы данных и их приложения менее зависимыми от конкретной СУБД.
Статья не претендует на оригинальность. В ней я собрал несколько приемов, которые часто использую при доработке функционала типовых конфигурация 1С:Предприятие 8.3 без внесения изменений в конфигурации поставщика. Материал будет полезен как начинающему программисту 1С, так, возможно, и профессиональному разработчику.
На практике, при разработке какого-нибудь дополнительного функционала с использованием механизма расширений или дополнительных обработок, возникает необходимость хранения каких-либо данных. Например, для внешней обработки загрузки данных товарной накладной из файла необходимо использовать одного и того же контрагента или группу номенклатуры. Можно конечно сразу прописать эти значения в коде используя метод менеджера справочника НайтиПоКоду() или использовать механизм Хранилища настроек. При использовании расширения можно создать Константу, Справочник или Регистр сведений, в которых можно хранить значения любого типа. Однако все описанные способы имеют свои недостатки: первый привязан к конкретной ИБ, второй к пользователю, данные расширения можно потерять в случае случайного удаления расширения.
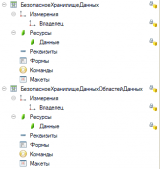
В своей практике я использую другой способ: в конфигурациях, использующих Библиотеку стандартных подсистем, есть встроенные объекты и процедуры для хранения каких либо данных настроек. Это два регистра сведений - БезопасноеХранилищеДанных и БезопасноеХранилищеДанныхОбластейДанных .

Эти регистры предназначены для хранения какой-либо конфиденциальной информации. В качестве измерения Владелец можно использовать ссылку на элемент Плана обмена, Справочника или использовать строку до 128 символов. Тип ресурса Данные - ХранилищеЗначения, в который обычно записывается данные типа Структура. Данные такого регистра просто не "вытащить" в пользовательском режиме универсальным отчетом или консолью запросов. Конечно, кроме паролей и токенов, можно хранить данные других типов.
Чтобы не разбираться какой из регистров когда использовать, для работы с этими регистрами сведений имеется программный интерфейс - процедура и функция общего модуля ОбщегоНазначения :
В качестве Владельца, как уже писалось выше, можно передать ссылку на элемент Плана обмена или Справочника, или просто строку. Ключ должен соответствовать правилам, установленным для идентификаторов. В качестве Данных передается значение произвольного типа, обычно строка или структура.
Пример реализации
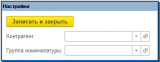
Рассмотрим пример сохранения каких-либо настроек Дополнительной обработки. Для этого создадим форму Настройки. В форме создадим команду ЗаписатьИЗакрыть и выведем ее в виде кнопки по умолчанию.
Форма будет иметь реквизиты для редактирования: ГруппаНоменклатуры и Контр агент , и два служебных: КлючДанных и ДополнительнаяОбработкаСсылка .

Поместим в модуль формы следующий код:
В процедуре ПриСозданииНаСервере проверяются параметры, переданные в форму. Если параметры содержат свойство ДополнительнаяОбработкаСсылка , то это значит что форма открыта с использованием подсистемы ДополнительныеОтчетыИОбработки и в качестве владельца настроек будет использован элемент справочника ДополнительныеОтчетыИОбработки. В противном случае владельцем будет строка - полное имя обработки. После определения владельца считываем данные из регистра с использованием функции программного интерфейса, и, если сохранённые данные редставляют собой структуру, заполняем ими значения реквизитов формы . Теперь при создании формы в значения реквизитов будут установлены ранее сохранённые значения.
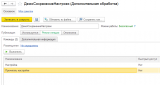
Обработку команды ЗаписатьИЗакрыть передадим на сервер. Там сформируем структуру из значений всех полей, которые выведены на форму. И эту структуру запишем в регистр, используя процедуру программного интерфейса Библиотеки стандартных подсистем.
Собственно, с формой настроек дополнительной обработки всё. Подобный механизм можно использовать и для хранения дополнительных данных справочника, если для него не включен механизм ДополнительныеРеквизитыИСведения, либо нет подходящего типа значения дополнительного реквизита.
Дополнительная обработка
Бонусом добавлю пример использования описанного механизма в дополнительной обработке, который можно использовать в качестве шаблона. В модуль объекта вставим следующий код:
Дополнительная обработка будет выполнять две команды на клиенте: Настройка и Выполнить . Для обработки логики этих команд создадим еще одну форму нашей обработки - ОсновнаяФорма и сделаем ее формой обработки по умолчанию.
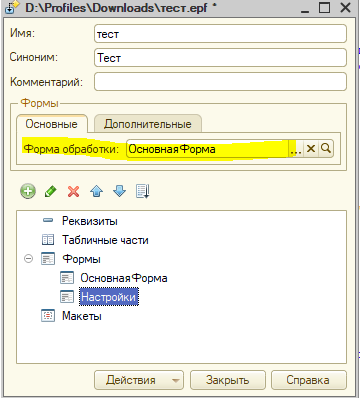
Конечно, для данного примера можно было использовать только форму Настройки, однако я хочу продемонстрировать открытие разных форм одной Дополнительной обработки. Необходимо так же, как и в форме Настройки, создать служебный реквизит формы ДополнительнаяОбработкаСсылка . В модуле формы создадим следующие процедуры и функции:
В процедуре ПриСозданииНаСервере производится чтение переданного через параметры формы свойства ДополнительнаяОбработкаСсылка , которое указывает на элемент справочника ДополнительныеОтчетыИОбработки. Экспортная процедура ВыполнитьКоманду вызывается программным интерфейсом подсистемы ДополнительныеОтчетыИОбработк. В ней, в зависимости от переданного параметра - идентификатора команды, открывается либо форма настроек, либо производится чтение отображение и настроек. Поскольку в БСП права на чтение и запись описываемых регистров хранения настроек доступны только для роли ПолныеПрава, то перед чтением сохраненных данных в функции Сохранены еДанные установим привилегированный режим. В этом случае доступ к настройкам может получить пользователь, в независимости от установленных прав. Хочу обратить внимание, как в функции Сохранены еДанные реализовано соединение строк. В отличие от традиционного соединения строк в цикле вида Стр=Стр+Значение , строки сначала помещаются в массив, а затем с помощью функции СтрСоединить соединяются. Этот вариант рекомендован для сложения строк в цикле с большим числом итераций , так как дает ощутимый выигрыш в производительности при крупных многопользовательских системах.
Описанные механизмы и процедуры можно использовать для собственных дополнительных обработок, поэтому файл я не прилагаю.
Читайте также: