
Data scientist что за профессия и data engineer
Опубликовано: 02.10.2024
Профессии Data Scientist и Data Engineer часто путают. У каждой компании своя специфика работы с данными, разные цели их анализа и разное представление, кто из специалистов какой частью работы должен заниматься, поэтому и требования каждый предъявляет свои.
Разбираемся, в чём разница между этими специалистами, какие задачи бизнеса они решают, какими навыками обладают и сколько зарабатывают.
Материал получился большим, поэтому разделили его на две публикации. В первой части рассказываем об основных отличиях Data Scientist и Data Engineer и с какими инструментами они работают.

Елена Герасимова
Руководитель факультета « Аналитика и Data Science » в Нетологии
Как различаются роли дата-инженеров и дата-сайентистов
Инженер данных — это специалист, который, с одной стороны, разрабатывает, тестирует и поддерживает инфраструктуру работы с данными: базы данных, хранилища и системы массовой обработки. С другой стороны, дата-инженер очищает и «причёсывает» данные для использования аналитиками и дата-сайентистами, то есть создаёт конвейеры обработки данных.
Дата-сайентист создаёт и обучает предиктивные (и не только) модели с помощью алгоритмов машинного обучения и нейросетей, помогая бизнесу находить скрытые закономерности, прогнозировать развитие событий и оптимизировать ключевые бизнес-процессы.
Главное различие между Data Scientist и Data Engineer состоит в том, что обычно у них разные цели. Оба работают для того, чтобы данные были доступными и качественными. Если дата-сайентист находит ответы на свои вопросы и проверяет гипотезы в экосистеме данных (например, на базе Hadoop), то дата-инженер создаёт пайплайн обслуживания алгоритма машинного обучения, написанного дата-сайентистом, в кластере Spark внутри той же экосистемы.
Инженер данных приносит ценность бизнесу, работая в команде. Он выступает важным звеном между различными участниками: от разработчиков до бизнес-потребителей отчетности. Также помогает повысить продуктивность аналитиков — от маркетинговых и продуктовых до BI.
Дата-сайентист принимает активное участие в стратегии компании и извлечении инсайтов, принятии решений, внедрении алгоритмов автоматизации, моделирования и генерации ценности из данных.

Работа с данными подчиняется принципу GIGO (garbage in — garbage out): если аналитики и дата-сайентисты имеют дело с неподготовленными и потенциально некорректными данными, то результаты даже с помощью самых изощрённых алгоритмов анализа будут неверны.
Инженеры данных решают эту проблему, выстраивая пайплайны по обработке, очистке и трансформации данных и позволяя дата-сайентисту работать уже с качественными данными.
На рынке много инструментов для работы с данными на каждом этапе: от их появления до вывода на дашборд для совета директоров. И важно, чтобы решение об их использовании принималось дата-инженером, — не потому, что это модно, а потому что он действительно поможет в работе остальным участникам процесса.
Условно: если компании нужно подружить BI и ETL — загрузку данных и обновления отчётов, вот типичный legacy-фундамент, с которым придётся иметь дело Data Engineer (хорошо, если в команде кроме него будет ещё и архитектор).
Обязанности Data Engineer
- Разработка, построение и обслуживание инфраструктуры работы с данными.
- Обработка ошибок и создание надёжных конвейеров обработки данных.
- Приведение неструктурированных данных из различных динамических источников к виду, необходимому для работы аналитиков.
- Предоставление рекомендаций по повышению консистентности и качества данных.
- Обеспечение и поддержка архитектуры данных, используемой дата- сайентистами и аналитиками данных.
- Обработка и хранение данных последовательно и эффективно в распределённом кластере на десятки или сотни серверов.
- Оценка технических компромиссов инструментов для создания простых, но надёжных архитектур, которые смогут пережить сбои.
- Контроль и поддержка потоков данных и связанных систем (настройка мониторинга и алертов).
Существует ещё одна специализация внутри траектории Data Engineer — ML Engineer. Если коротко, то такие инженеры специализируются на доведении моделей машинного обучения до промышленного внедрения и использования. Зачастую модель, которая поступила от дата-сайентиста, является частью исследования и может не заработать в боевых условиях.
Профессия
Дата-инженер с нуля до PRO 💪
Узнать больше
- Научитесь автоматизировать работу с данными, настраивать мониторинги, создавать конвейеры обработки и схемы хранения данных
- Получите знания, равноценные опыту 2‒3 лет самостоятельного изучения инжиниринга данных
Обязанности Data Scientist
- Извлечение признаков из данных для применения алгоритмов машинного обучения.
- Использование различных инструментов машинного обучения для прогнозирования и классификации паттернов в данных.
- Повышение производительности и точности алгоритмов машинного обучения за счет тонкой настройки и оптимизации алгоритмов.
- Формирование «сильных» гипотез в соответствии со стратегией компании, которые необходимо проверить.
И Data Engineer, и Data Scientist объединяет ощутимый вклад в развитие культуры работы с данными, с помощью которой компания может получать дополнительную прибыль или сокращать издержки.
С какими языками и инструментами работают инженеры данных и дата-сайентисты
Ожидания от специалистов по обработке данных изменились. Раньше дата-инженеры собирали большие SQL-запросы, вручную писали MapReduce и обрабатывали данные с помощью таких инструментов, как Informatica ETL, Pentaho ETL, Talend.
В 2020 году специалисту не обойтись без знания Python и современных инструментов проведения вычислений (например, Airflow), понимания принципов работы с облачными платформами — использования их для экономии на «железе», при соблюдении принципов безопасности.
SAP, Oracle, MySQL, Redis — это традиционные для инженера данных инструменты в больших компаниях. Они хороши, но стоимость лицензий настолько высока, что учиться работать с ними имеет смысл только в промышленных проектах. При этом, есть альтернатива в виде Postgres — он бесплатный и подходит не только для обучения.

Исторически часто встречается запрос на Java и Scala, хотя по мере развития технологий и подходов эти языки отходят на второй план.
Тем не менее, хардкорная BigData: Hadoop, Spark и остальной зоопарк — это уже не обязательное условие для инженера данных, а разновидность инструментов для решения задач, которые не решить традиционным ETL.
В тренде — сервисы для использования инструментов без знания языка, на котором они написаны (например, Hadoop без знания Java), а также предоставление готовых сервисов для обработки потоковых данных — распознавание голоса или образов на видео.
Популярны промышленные решения от SAS и SPSS, при этом Tableau, Rapidminer, Stata и Julia также широко используются дата-сайентистами для локальных задач.

Возможность самим строить пайплайны появилась у аналитиков и дата-сайентистов всего пару лет назад. Например, уже можно относительно несложными скриптами направлять данные в хранилище на основе PostgreSQL.
Обычно использование конвейеров и интегрированных структур данных остаётся в ведении дата-инженеров. Но сегодня как никогда силён тренд на Т-образных специалистов — с широкими компетенциями в смежных областях, ведь инструменты постоянно упрощаются.
Профессия
Data Scientist
Узнать больше
- Научитесь строить и обучать предиктивные модели с помощью алгоритмов машинного обучения и нейросетей
- Будете находить скрытые закономерности, прогнозировать развитие событий и оптимизировать ключевые бизнес-процессы
Зачем Data Engineer и Data Scientist работать вместе
Работая в тесном сотрудничестве с дата-инженерами, дата-сайентисты могут сосредоточиться на исследовательской части и создавать готовые к работе алгоритмы машинного обучения. А инженеры — сфокусироваться на масштабируемости, повторном использовании данных, а также гарантировать, что пайплайны ввода и вывода данных в каждом отдельно взятом проекте соответствуют глобальной архитектуре.
Такое разделение обязанностей обеспечивает согласованность действий между группами специалистов, работающими над разными проектами машинного обучения.
Сотрудничество помогает эффективно создавать новые продукты. Скорость и качество достигаются, благодаря балансу между созданием сервиса для всех (глобальное хранилище или интеграция дашбордов) и реализацией каждой конкретной потребности или проекта (узкоспециализированный пайплайн, подключение внешних источников).
Тесная работа с дата-сайентистами и аналитиками помогает инженерам развивать аналитические и исследовательские навыки для написания более качественного кода. Улучшается обмен знаниями между пользователями хранилищ и озёр данных, что делает проекты более гибкими и обеспечивает более устойчивые долгосрочные результаты.
В компаниях, которые ставят своей целью развитие культуры работы с данными и выстраивание бизнес-процессов на их основе, Data Scientist и Data Engineer дополняют друг друга и создают полноценную систему анализа данных.
В следующем материале расскажем о том, какое образование должно быть у Data Engineer и Data Scientists, какие навыки им нужно развивать и сколько зарабатывают специалисты.
Материал изначально опубликован на habr .
ЧИТАТЬ ТАКЖЕ
Хотите написать колонку для Нетологии? Читайте наши условия публикации . Чтобы быть в курсе всех новостей и читать новые статьи, присоединяйтесь к Телеграм-каналу Нетологии .

Развитие науки о данных дало старт нескольким профессиям с префиксом «дата-», которые несложно перепутать. Работа дата-сайентиста и дата-инженера во многом похожа, но эти специалисты не взаимозаменяемы и выполняют разные задачи. Позиция Data Engineer — прикладная, а Data Scientist — более творческая и аналитическая.
Кто такие исследователи данных и дата-инженеры?
Дата-инженер разрабатывает, строит, тестирует и поддерживает архитектуру данных: крупные базы данных, хранилища или системы для обработки информации. Он работает с сырыми данными, перерабатывает их и строит пайплайны (схемы по их обслуживанию) — то есть подготавливает материал для использования дата-сайентистами.
Дата-сайентист использует обработанные дата-инженером данные, чтобы построить прогнозные модели и решить те или иные бизнес-задачи. Такой специалист использует методы описательной статистики для анализа и систематизирования данных и строит модели с помощью алгоритмов машинного обучения, чтобы снабжать бизнес прогнозами и инсайтами.
Что Data Scientist и Data Engineer могут делать в одной компании?
У исследователя данных и дата-инженера обычно разные цели. Первый непосредственно решает запросы бизнеса: для этого он проверяет гипотезы и строит прогнозные модели. Второй отвечает за оптимальное и надежное хранение данных, их преобразование, а также за быстрый и удобный доступ к ним. Это позволяет дата-сайентисту работать с корректными и актуальными данными.
Компании, которые хотят использовать Data Science для развития своего бизнеса, могут нанимать и дата-инженера, и дата-сайентиста.
Пример: в онлайн-магазине бытовой техники каждый раз, когда посетитель сайта нажимает на тот или иной товар, создается новый элемент данных.
Дата-инженер может собрать эти данные и сохранить в удобном для доступа формате. Дата-сайентист получает данные о том, какие клиенты купили те или иные товары, и использует эту информацию так, чтобы предсказать вариант идеального предложения для каждого нового посетителя сайта.
Пример: работа в платной онлайн-библиотеке. Если компания хочет узнать, какие пользователи тратят больше денег, им нужны компетенции и дата-сайентиста, и дата-инженера. Инженер соберет информацию из логов сервера и журналов событий сайта и создаст пайплайн, который соотносит данные с конкретным пользователем. Затем инженеру нужно будет обеспечить хранение полученной информации в базе данных так, чтобы ее можно было без труда запросить. После этого дата-сайентист сможет проанализировать действия пользователей сайта и узнать особенности поведения тех, кто тратит больше денег.
Что именно делает исследователь данных, а что — дата-инженер?
Часть навыков этих специалистов пересекается (например, в области доступа к данным или программирования), но специализация у них разная. Дата-инженер — более прикладная позиция, она направлена на кропотливую работу по формированию пайплайнов данных и их дальнейшему поддержанию. Работа дата-сайентиста — более творческая и аналитическая.
Обязанности дата-сайентиста:
- проводить анализ и исследование данных, чтобы решать бизнес-задачи;
- использовать большие объемы данных из внутренних и внешних источников, чтобы отвечать на запросы бизнеса;
- использовать аналитические программы, машинное обучение и статистику для прогнозирования;
- исследовать данные, чтобы находить скрытые закономерности;
- подавать полученную информацию в доступном формате акционерам и руководителям.
Для прохождения курса вам не потребуется специальных знаний, выходящих за рамки школьной программы. Вы получите достаточную математическую подготовку и опыт программирования на Python, чтобы решать задачи машинного обучения.
Как написать программу по распознаванию лица за 2 часа?
Под руководством эксперта вы напишете программу на Python, которая распознает лицо на фотографии или через веб-камеру, а также узнаете, где вы сможете это применять. 30 МАЯ, 12:00 (МСК)
Записаться на вебинар
Обязанности инженера данных:
- разрабатывать, строить, тестировать и поддерживать архитектуру данных;
- обеспечивать актуальность и пригодность архитектуры данных для бизнеса;
- искать новые возможности для получения данных;
- разрабатывать процессы создания наборов данных для моделирования, майнинга и производства;
- давать рекомендации по улучшению эффективности, качества хранения и надежности данных.
В рамках курса вас ждет сквозной проект — реальная задача дата-инженера. На каждом новом этапе вы будете решать часть большой задачи и в финале автоматизируете весь процесс.
Какую профессию выбрать?
На практике четкая граница между специальностями дата-сайентиста и инженера данных существует только в IT-компаниях и крупных корпорациях с большими IT-отделами. Специалист по Data Science часто сочетает навыки смежных позиций — он должен подстроиться под конкретную задачу и решить ее.
Изучать науку о данных можно и без технического бэкграунда и умения программировать. Так как позиции дата-аналитика, дата-сайентиста и дата-инженера близки, при необходимости можно будет довольно быстро поменять специализацию.
Помимо этих двух специальностей, есть и другие, связанные с наукой о данных: дата-аналитик, администратор баз данных, менеджер данных, бизнес-аналитик, маркетолог-аналитик, ML-инженер. Все они подразумевают работу с данными и требуют изучения базовых понятий Data Science.
Оптимальный путь для начинающего специалиста — освоить базовые навыки Data Science, а уже затем углубиться в ту область, которая покажется самой интересной.
Вместе с Еленой Герасимовой, руководителем факультета « Data Science и аналитика » в Нетологии продолжаем разбираться, как взаимодействуют между собой и чем различаются Data Scientist и Data Engineer.
В этом материале поговорим о том, какими знаниями и навыками должны обладать специалисты, какое образование ценится работодателями, как проходят собеседования, а также сколько зарабатывают дата-инженеры и дата-сайентисты.
Что должны знать сайентисты и инженеры
Профильное образование для обоих специалистов — Computer Science.
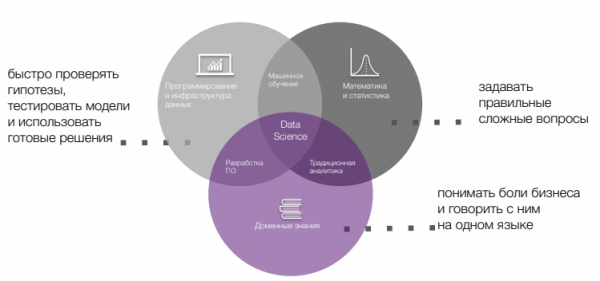
Любой специалист по данным — дата-сайентист или аналитик — должен уметь доказывать корректность своих выводов. Для этого не обойтись без знания статистики и связанной со статистикой базовой математики.
Машинное обучение и инструменты анализа данных незаменимы в современном мире. Если привычные инструменты недоступны, нужно иметь навыки быстрого изучения новых инструментов, создания простых скриптов для автоматизации задач.
Важно отметить, что специалист по работе с данными должен эффективно донести результаты анализа. В этом ему поможет визуализация данных или результатов проведённых исследований и проверки гипотез. Специалисты должны уметь создавать диаграммы и графики, использовать инструменты визуализации, понимать и разъяснять данные из дашбордов.
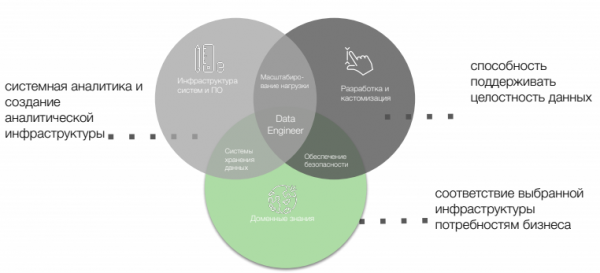
Для инженера данных на первый план выходят три направления.
Алгоритмы и структуры данных. Важно набить руку в написании кода и использовании основных структур и алгоритмов:
- анализ сложности алгоритмов,
- умение писать понятный, поддерживаемый код,
- пакетная обработка,
- обработка в реальном времени.
Базы и хранилища данных, Business Intelligence:
- хранение и обработка данных,
- проектирование целостных систем,
- Data Ingestion,
- распределенные файловые системы.
Hadoop и Big Data. Данных становится всё больше, и на горизонте 3‒5 лет эти технологии станут необходимы каждому инженеру. Плюс:
- Data Lakes,
- работа с облачными провайдерами.
Машинное обучение будет использоваться повсеместно, и важно понимать, какие бизнес-задачи оно поможет решить. Не обязательно уметь делать модели (с этим справятся дата-сайентисты), но нужно разбираться в их применении и соответствующим требованиям.
Сколько получают инженеры и сайентисты
Доход инженеров по обработке данных
В международной практике начальная зарплата обычно составляет $100 000 в год и значительно увеличивается с опытом, по данным Glassdoor. Кроме того, компании часто предоставляют опционы на акции и 5‒15% годовых бонусов.
В России в начале карьеры зарплата обычно не меньше 50 тыс. рублей в регионах и 80 тыс. в Москве. На этом этапе не требуется опыт, кроме пройденного обучения.
Через 1‒2 года работы — вилка 90‒100 тыс. рублей.
Вилка увеличивается до 120‒160 тыс. через 2‒5 лет. Добавляются такие факторы, как специализация прошлых компаний, размер проектов, работа с big data и прочее.
После 5 лет работы легче искать вакансии в смежных отделах или откликаться на такие узкоспециализированные позиции, как:
- Архитектор или ведущий разработчик в банке или телеком — около 250 тыс.
- Pre-Sales у вендора, с технологиями которого вы работали плотнее всего, — 200 тыс. плюс возможен бонус (1‒1,5 млн рублей).
- Эксперты по внедрению Enterprise business application, таких как SAP, — до 350 тыс.
Доход дата-сайентистов
Исследование рынка аналитиков компании «Нормальные исследования» и рекрутингового агентства New.HR показывает, что специалисты по Data Science получают в среднем большую зарплату, чем аналитики других специальностей.
В России начальная зарплата дата-сайентиста с опытом работы до года — от 113 тыс. рублей.
В качестве опыта работы сейчас также учитывается прохождение обучающих программ.
Через 1‒2 года такой специалист уже может получать до 160 тыс.
Для сотрудника с опытом работы от 4‒5 лет вилка вырастает до 310 тыс.
Как проходят собеседования
На западе выпускники программ профессионального обучения проходят первое собеседование в среднем через 5 недель после окончания обучения. Около 85% находят работу через 3 месяца.
Процесс прохождения собеседований на вакансии инженера данных и дата-сайентиста практически не различается. Обычно состоит из пяти этапов.
Резюме. Кандидатам с непрофильным предыдущим опытом (например, из маркетинга) необходимо для каждой компании подготовить подробное сопроводительное письмо или иметь рекомендации от представителя этой компании.
Технический скрининг. Проходит, как правило, по телефону. Состоит из одного-двух сложных и столько же простых вопросов, касающихся текущего стека работодателя.
HR-интервью. Может проходить по телефону. На этом этапе кандидата проверяют на общую адекватность и способность общаться.
Техническое собеседование. Чаще всего проходит очно. В разных компаниях уровень позиций в штатном расписании отличается, и называться позиции могут по-разному. Поэтому на этом этапе проверяют именно технические знания.
Собеседование с техническим директором / главным архитектором. Инженер и сайентист — стратегические позиции, а для многих компаний к тому же новые. Важно, чтобы потенциальный коллега понравился руководителю и совпадал с ним во взглядах.
Что поможет сайентистам и инженерам в карьерном росте
Появилось достаточно много новых инструментов по работе с данными. И мало кто одинаково хорошо разбирается во всех.
Многие компании не готовы нанимать сотрудников без опыта работы. Однако кандидаты с минимальной базой и знанием основ популярных инструментов могут получить нужный опыт, если будут обучаться и развиваться самостоятельно.
Полезные качества для дата-инженера и дата-сайентиста
Желание и умение учиться. Необязательно сразу гнаться за опытом или менять работу ради нового инструмента, но нужно быть готовым переключиться на новую область.
Стремление к автоматизации рутинных процессов. Это важно не только для продуктивности, но и для поддержания высокого качества данных и скорости их доставки до потребителя.
Внимательность и понимание «что там под капотом» у процессов. Быстрее решит задачу тот специалист, у которого есть насмотренность и доскональное знание процессов.
Кроме отличного знания алгоритмов, структур данных и пайплайнов, нужно научиться мыслить продуктами — видеть архитектуру и бизнес-решение как единую картину.
Например, полезно взять любой известный сервис и придумать для него базу данных. Затем подумать, как разработать ETL и DW, которые наполнят её данными, какие будут потребители и что им важно знать о данных, а также как покупатели взаимодействуют с приложениями: для поиска работы и знакомств, прокат автомобилей, приложение для подкастов, образовательная платформа.
Позиции аналитика, дата-сайентиста и инженера очень близки, поэтому переходить из одного направления в другое можно быстрее, чем из других сфер.
В любом случае, обладателям любого ИТ-бэкграунда будет проще, чем тем, у кого его нет. В среднем взрослые мотивированные люди переучиваются и меняют работу каждые 1,5‒2 года. Легче это даётся тем, кто учится в группе и с наставником, по сравнению с теми, кто опирается лишь на открытые источники.
От редакции Нетологии
Если присматриваетесь к профессии Data Engineer или Data Scientist, приглашаем изучить программы наших курсов:
Сейчас все вокруг говорят о том, как важно собирать данные, анализировать их и использовать для улучшения клиентского сервиса, оптимизации бизнес-процессов и увеличения прибыли. Всем этим занимаются Data Scientist. По статистике LinkedIn, с 2018 года в мире наняли 831 тысячу таких специалистов.
Мы поговорили с Иваном Пастуховым, Data Scientist из Сбербанка, и другими экспертами — расскажем, кто такие специалисты по Data Science, какие у них обязанности, что они должны уметь и как понять, нужен ли вашей компании такой специалист.
Data Scientist — кто это и что делает
Дословно Data Scientist переводится как «ученый данных». Но деятельность у такого специалиста не научная, а практическая: он работает с данными компании, анализирует их, ищет зависимости, делает выводы на их основе и при необходимости строит визуализации. Для этого Data Scientist использует разные математические алгоритмы, специальное программное обеспечение и инструменты разработки.
Данные, с которыми работает Data Scientist, могут быть любыми: звук, текст, фото, видео, таблицы, документы. Если у вас есть любые данные и нужно их проанализировать — это работа для Data Scientist.
В сфере данных работают и другие специалисты, например, Machine Learning Engineer, Data Engineer или Data Analyst. У них более узкая специализация, например, Machine Learning Engineer меньше занимается анализом данных, в основном разрабатывает модели машинного обучения. Data Scientist — более широкий термин, который обозначает человека с разными компетенциями в области анализа данных.
Обычно компании на старте нанимают одного Data Scientist. В будущем, если разноплановых задач, связанных с данными, станет слишком много, можно нанять несколько таких специалистов, то есть создать целый отдел Data Science.
Чем занимается Data Scientist
Часто в бизнесе есть задачи, которые решаются вручную. Например, менеджер делает простенькие расчеты в Excel или руководитель магазина по своему опыту предсказывает спрос на товары. Такие ручные решения занимают много времени и часто необъективны.
Data Scientist автоматизирует принятие таких решений и делает их более точными, основанными на данных. Он разбирается в задаче, смотрит, какие данные нужны для ее решения. Потом разрабатывает программу, которая будет автоматически считать и анализировать данные. Такая программа может либо принимать простые решения самостоятельно, либо давать более точную и полезную информацию менеджерам.
Часто Data Scientist решает общие задачи, характерные для любого бизнеса: проанализировать поведение покупателей, привлечь и удержать клиента, предугадать спрос, построить систему рекомендаций, запустить эффективную акцию. Но бывают и специфические задачи: банк хочет предсказать вероятность возврата кредита, колл-центр — автоматизировать ответы на часто задаваемые вопросы. С этим тоже помогает Data Scientist. Бывает и так, что Data Scientist не решает конкретную задачу, а анализирует текущую ситуацию и ищет зоны роста для компании.
В разных компаниях Data Scientist занимаются совсем разными вещами. Но в итоге они делают одно дело: помогают сэкономить деньги, увеличить доход или принять правильное решение.
Как понять, что вашей компании нужен Data Scientist
Если компания связана с технологиями, например, разработкой искусственного интеллекта или инструментов автоматизации, Data Scientist ей нужен с самого старта.
Если компания напрямую не связана с IT, Data Scientist обычно становится нужен, когда данных и бизнес-процессов много, ими сложно управлять вручную. Обычно такое происходит в крупных компаниях, которые уже перепробовали разные способы увеличить прибыль и пришли к тому, что нужно извлекать новую информацию из собранных данных, автоматизировать отдельные процессы и искать другие подходы к работе с клиентами.
Впрочем, иногда Data Scientist может быть полезен и небольшой компании. Он подскажет, как стоит собирать данные, что можно автоматизировать, где искать проблемы и зоны роста.
Что нужно Data Scientist для работы
Главное, с чем работает Data Scientist — это данные. Компания должна уже собирать, обрабатывать и хранить данные, построить для этого соответствующую инфраструктуру.
Data Scientist обрабатывает данные, для чего часто требуются большие вычислительные мощности и специальные инструменты.
Еще для работы Data Scientist нуждается в команде помощников. Чаще всего он работает в связке с Data Engineer и командой разработчиков. Первые обеспечивают его данными, вторые превращают разработанные модели в конкретные программы и сервисы, которыми могут пользоваться другие люди.
В небольших компаниях Data Scientist часто сам себе и Engineer, и разработчик. В более крупных за Data Science может отвечать целый отдел, состоящий из разных специалистов.
Что нужно знать Data Scientist
Data Science — дисциплина, которая лежит на стыке математики, статистики и компьютерных наук. Поэтому обычно Data Scientist должен:
- Знать математику и статистику.
- Писать код, обычно на языках R и Python.
- Работать с базами данных и знать язык SQL.
- Владеть инструментами для работы с большими данными: Hadoop, Spark, Hive, Kafka.
- Отлаживать код и готовить к выкатке в продакшен.
- Работать с программами для визуализации и презентации результатов работы: PowerPoint, Shiny/Dash, Power BI, Tableau, Qlik
- Знать технологии машинного и глубокого обучения.
В вузах пока редко встречается специальность Data Scientist. Те, кто задаются вопросом «Как стать Data Scientist» обычно учатся на курсах, либо поступают в университеты на прикладную математику или специальности, связанные с математическим моделированием. Хотя кое-где, например в ВШЭ, есть магистерские программы, посвященные анализу данных и машинному обучению.
Профессии Data Scientist и Data Engineer часто путают. У каждой компании своя специфика работы с данными, разные цели их анализа и разное представление, кто из специалистов какой частью работы должен заниматься, поэтому и требования каждый предъявляет свои.
Разбираемся, в чём разница этих специалистов, какие задачи бизнеса они решают, какими навыками обладают и сколько зарабатывают. Материал получился большим, поэтому разделили его на две публикации.
В первой статье Елена Герасимова, руководитель факультета «Data Science и аналитика» в Нетологии, рассказывает, в чём разница между Data Scientist и Data Engineer и с какими инструментами они работают.
Как различаются роли инженеров и сайентистов
Инженер данных — это специалист, который, с одной стороны, разрабатывает, тестирует и поддерживает инфраструктуру работы с данными: базы данных, хранилища и системы массовой обработки. С другой стороны — это тот, кто очищает и «причёсывает» данные для использования аналитиками и дата-сайентистами, то есть создаёт конвейеры обработки данных.
Data Scientist создаёт и обучает предиктивные (и не только) модели с помощью алгоритмов машинного обучения и нейросетей, помогая бизнесу находить скрытые закономерности, прогнозировать развитие событий и оптимизировать ключевые бизнес-процессы.
Главное различие между Data Scientist и Data Engineer состоит в том, что обычно у них разные цели. Оба работают для того, чтобы данные были доступными и качественными. Но Data Scientist находит ответы на свои вопросы и проверяет гипотезы в экосистеме данных (например, на базе Hadoop), а Data Engineer — создаёт пайплайн обслуживания алгоритма машинного обучения, написанного дата-сайентистом, в кластере Spark внутри той же экосистемы.
Инженер данных приносит ценность бизнесу, работая в команде. Его задача — выступить важным звеном между разными участниками: от разработчиков до бизнес-потребителей отчетности, — и повысить продуктивность аналитиков — от маркетинговых и продуктовых до BI.
Data Scientist же, напротив, принимает активное участие в стратегии компании и извлечении инсайтов, принятии решений, внедрении алгоритмов автоматизации, моделирования и генерации ценности из данных. 
Работа с данными подчиняется принципу GIGO (garbage in — garbage out): если аналитики и дата-сайентисты имеют дело с неподготовленными и потенциально некорректными данными, то результаты даже с помощью самых изощрённых алгоритмов анализа будут неверны.
Инженеры данных решают эту проблему, выстраивая пайплайны по обработке, очистке и трансформации данных и позволяя дата-сайентисту работать уже с качественными данными.
На рынке много инструментов для работы с данными, которые покрывают каждый из этапов: от появления данных до вывода на дашборд для совета директоров. И важно, чтобы решение об их использовании принималось инженером, — не потому, что это модно, а потому что он действительно поможет в работе остальным участникам процесса.
Условно: если компании нужно подружить BI и ETL — загрузку данных и обновления отчётов, вот типичный legacy-фундамент, с которым придётся иметь дело Data Engineer (хорошо, если в команде кроме него будет ещё и архитектор).
Обязанности Data Engineer
- Разработка, построение и обслуживание инфраструктуры работы с данными.
- Обработка ошибок и создание надёжных конвейеров обработки данных.
- Приведение неструктурированных данных из различных динамических источников к виду, необходимому для работы аналитиков.
- Предоставление рекомендаций по повышению консистентности и качества данных.
- Обеспечение и поддержка архитектуры данных, используемой дата- сайентистами и аналитиками данных.
- Обработка и хранение данных последовательно и эффективно в распределенном кластере на десятки или сотни серверов.
- Оценка технических компромиссов инструментов для создания простых, но надежных архитектур, которые смогут пережить сбои.
- Контроль и поддержка потоков данных и связанных систем (настройка мониторинга и алертов).
Обязанности Data Scientist
- Извлечение признаков из данных для применения алгоритмов машинного обучения.
- Использование различных инструментов машинного обучения для прогнозирования и классификации паттернов в данных.
- Повышение производительности и точности алгоритмов машинного обучения за счет тонкой настройки и оптимизации алгоритмов.
- Формирование «сильных» гипотез в соответствии со стратегией компании, которые необходимо проверить.
С какими языками и инструментами работают инженеры и сайентисты
Сегодня ожидания от специалистов по обработке данных изменились. Раньше инженеры собирали большие SQL-запросы, вручную писали MapReduce и обрабатывали данные с помощью таких инструментов, как Informatica ETL, Pentaho ETL, Talend.
В 2020 году специалисту не обойтись без знания Python и современных инструментов проведения вычислений (например Airflow), понимания принципов работы с облачными платформами (использования их для экономии на «железе», при соблюдении принципов безопасности).
SAP, Oracle, MySQL, Redis — это традиционные для инженера данных инструменты в больших компаниях. Они хороши, но стоимость лицензий настолько высока, что учиться работать с ними имеет смысл только в промышленных проектах. При этом есть бесплатная альтернатива в виде Postgres — он бесплатный и подходит не только для обучения.

Исторически часто встречается запрос на Java и Scala, хотя по мере развития технологий и подходов эти языки отходят на второй план.
Тем не менее, хардкорная BigData: Hadoop, Spark и остальной зоопарк — это уже не обязательное условие для инженера данных, а разновидность инструментов для решения задач, которые не решить традиционным ETL.
Популярны промышленные решения от SAS и SPSS, при этом Tableau, Rapidminer, Stata и Julia также широко используются дата-сайентистами для локальных задач.

Возможность самим строить пайплайны появилась у аналитиков и дата-сайентистов всего пару лет назад: например, уже можно относительно несложными скриптами направлять данные в хранилище на основе PostgreSQL.
Обычно использование конвейеров и интегрированных структур данных остаётся в ведении дата-инженеров. Но сегодня как никогда силён тренд на Т-образных специалистов — с широкими компетенциями в смежных областях, ведь инструменты постоянно упрощаются.
Зачем Data Engineer и Data Scientist работать вместе
Работая в тесном сотрудничестве с инженерами, Data Scientist могут сосредоточиться на исследовательской части, создавая готовые к работе алгоритмы машинного обучения.
А инженеры — сфокусироваться на масштабируемости, повторном использовании данных и гарантировать, что пайплайны ввода и вывода данных в каждом отдельно взятом проекте соответствуют глобальной архитектуре.
Такое разделение обязанностей обеспечивает согласованность действий между группами специалистов, работающими над разными проектами машинного обучения.
Сотрудничество помогает эффективно создавать новые продукты. Скорость и качество достигаются, благодаря балансу между созданием сервиса для всех (глобальное хранилище или интеграция дашбордов) и реализацией каждой конкретной потребности или проекта (узкоспециализированный пайплайн, подключение внешних источников).
Тесная работа с дата-сайентистами и аналитиками помогает инженерам развивать аналитические и исследовательские навыки для написания более качественного кода. Улучшается обмен знаниями между пользователями хранилищ и озёр данных, что делает проекты более гибкими и обеспечивает более устойчивые долгосрочные результаты.
В компаниях, которые ставят своей целью развитие культуры работы с данными и выстраивание бизнес-процессов на их основе, Data Scientist и Data Engineer дополняют друг друга и создают полноценную систему анализа данных.
В следующем материале расскажем о том, какое образование должно быть у Data Engineer и Data Scientists, какие навыки им нужно развивать и как устроен рынок.
От редакции Нетологии
Если присматриваетесь к профессии Data Engineer или Data Scientist, приглашаем изучить программы наших курсов:
Читайте также: